RL Swarm: Рамкова система для спільного навчання з підкріпленням

Це відкритий програмний код (ліцензія MIT) для однорангових вузлів (P2P), які виконують спільне навчання з підкріпленням через інтернет. Система доступна для будь-якого користувача та працює на споживчому або датацентровому обладнанні.
Ми давно віримо, що майбутнє машинного навчання буде децентралізованим і фрагментованим. Наші поточні монолітні моделі будуть замінені на фрагментовані параметри, що існують на кожному пристрої по всьому світу. У нашому дослідженні ми вивчаємо різні шляхи, що ведуть до цього майбутнього, і нещодавно виявили, що навчання з підкріпленням (RL) працює особливо ефективно, коли моделі навчаються спільно, взаємодіючи одна з одною та критикуючи відповіді одна одної.
Ми прийшли до висновку, що RL-моделі навчаються швидше, коли вони навчаються як колективне співтовариство, а не поодинці.
Подробиці механізму читайте тут або приєднуйтесь до живої демонстрації, щоб побачити технологію в дії.
Як це працює
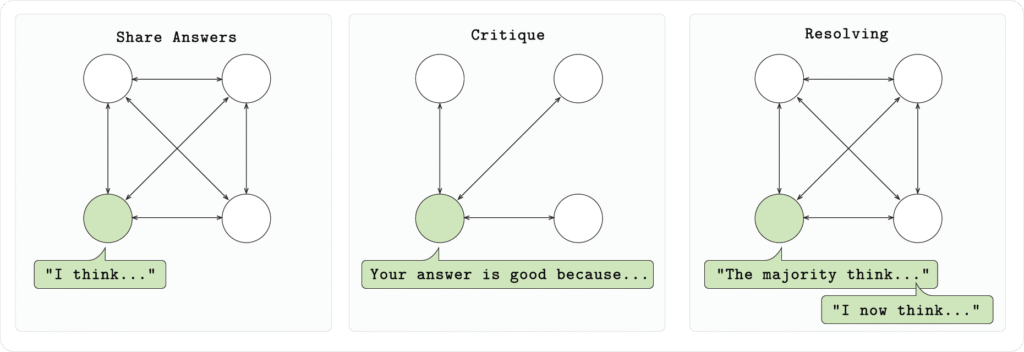
У нашій налаштуванні кожен вузол у співтоваристві запускає модель Qwen 2.5 1.5B і розв’язує математичні задачі (GSM8K) у три етапи:
- Етап 1 (Відповідь):
Кожна модель розв’язує задачу незалежно, виводячи своє міркування та відповідь у вказаному форматі.
- Етап 2 (Критика):
Кожна модель розглядає відповіді, надані іншими моделями, і дає свою зворотну реакцію.
- Етап 3 (Вирішення):
Кожна модель голосує за найкращу відповідь на кожне питання. Потім кожна модель надає остаточну переглянуту відповідь.
У наших експериментах ми виявили, що ця система прискорює навчання, дозволяючи моделям давати більш точні відповіді на невидених тестових даних з меншим числом кроків навчання.

Наведені вище графіки відображають результати з Tensorboard, отримані від одного вузла мережі (Swarm). На кожному графіку спостерігається циклічна поведінка, яка є артефактом «скидання» (reset) між раундами багатоетапної гри. На всіх графіках вісь X відображає час, що минув з моменту підключення до рою. На осі Y, рухаючись від крайнього лівого графіка до правого, ми бачимо:
i) «Винагорода за коректність консенсусу» (consensus correctness reward), яка фіксує випадки, коли цей учасник рою правильно форматував свої варіанти відповідей і коли обрана ним відповідь була математично правильною.
ii) Загальна винагорода (total reward), яка є зваженою сумою кількох винагород на основі правил (наприклад, перевірка форматування та математичної/логічної правильності відповідей).
iii) Втрати при навчанні (training loss), які відображають сигнал зворотного зв’язку для максимізації винагороди, що передається для оновлення «базової» ВММ (великої мовної моделі).
iv) Довжина відповіді моделі (response completion length), яка вимірює кількість токенів у вихідній відповіді (це демонструє, що моделі навчаються бути більш лаконічними під час критики з боку інших учасників).
Приєднання до спільноти
Для демонстрації цієї системи та масштабування експериментів ми випускаємо живу демонстрацію, до якої будь-який користувач може приєднатися. Це повністю відкрита система для створення навчальних спільнот RL через Інтернет.
Запуск swarm-node дозволяє вам створити новий роєвий кластер або підключитися до вже існуючого вузла, використовуючи його публічну адресу. Кожен кластер виконує обґрунтоване навчання з підкріпленням (RL) колективно, застосовуючи систему обміну плітками на базі Hivemind для спільного покращення моделей.
Запуск вбудованого клієнта дає змогу підключитися до кластера, отримувати повідомлення та локально навчати свою модель як частину колективу. У майбутньому ми запустимо ще більше експериментів для роєвої системи та будемо раді широкому участі спільноти.
***
RL Swarm — це погляд у майбутнє машинного навчання. Він надає рамкову систему для спільного RL між учасниками, де інтелект використовує колективну мудрість, а не обмежене коло закритих лабораторій. Масштабування вимагатиме відкритої обчислювальної мережі, що з’єднує кожен пристрій у світі. Подробиці — незабаром.