NoLoCo: навчання великих моделей без all-reduce

Це наукова стаття, яка описує NoLoCo, новий метод оптимізації розподіленого навчання, що замінює етап глобальної синхронізації методом gossip, дозволяючи проводити навчання в гетерогенних мережах з низькою пропускною здатністю.
Сучасні методи навчання великих моделей вимагають частого обміну градієнтами між вузлами, що потребує високошвидкісних і низькозатриманих з’єднань. В іншому випадку вузли залишаються бездіяльними в очікуванні оновлень. Раніше запропоновані методи, такі як DiLoCo, знижують вартість комунікації, зменшуючи частоту all-reduce, однак кожне подія все одно включає кожну репліку і, отже, успадковує ті ж обмеження по затримці.
Сьогодні ми розширюємо це напрямок досліджень за допомогою NoLoCo — методу, який повністю виключає глобальний крок all-reduce. Після короткого блоку локальних оновлень SGD репліки усереднюють ваги з однією випадковою реплікою, у той час як активації випадковим чином перенаправляються між етапами конвеєра. Використовується модифікований крок Нестерова для підтримки узгодженості параметрів. В експериментах із використанням до 1000 GPU, підключених через Інтернет, NoLoCo забезпечує таку ж точність на валідації, як стандартний паралелізм даних, при цьому знижуючи затримку синхронізації приблизно в 10 разів.
Основні моменти
- Без all-reduce
NoLoCo застосовує паралелізм даних, але виключає глобальну синхронізацію (all-reduce), обмінюючись даними тільки між маленькими парами вузлів. - Без втрат у швидкості збіжності
Розбіжність між репліками зменшується за рахунок випадкової маршрутизації активацій між етапами конвеєра і спеціального додавання в момент Нестерова, що контролює розбіжність ваг. - 10× швидше синхронізація на великому масштабі
При 1,000 реплік NoLoCo зберігає точність baseline, прискорюючи кожен крок синхронізації порівняно з tree all-reduce.
Основи
В стандартному навчанні з паралельною обробкою даних кожен робочий вузол обчислює градієнти на своєму міні-батчі, а потім бере участь в загальнокластерній операції all-reduce, щоб кожна репліка отримала однакове оновлення. Колективна комунікація масштабується лінійно з кількістю реплік і обмежується найбільш повільним з’єднанням. На вузлах, підключених через Інтернет, цей крок домінує по часу виконання і витрачає обчислювальні ресурси. Схеми з низьким рівнем комунікації, такі як DiLoCo, зменшують частоту виконання операції all-reduce, однак кожна синхронізація все одно зачіпає кожен робочий вузол, що призводить до однакових обмежень по затримці.
NoLoCo показує, що ми можемо уникнути цієї синхронізації all-reduce, не погіршуючи збіжність.
Як це працює
Замість виконання операції all-reduce, NoLoCo синхронізує тільки невеликі, випадково вибрані репліки (як мінімум дві). Це зменшує складність часу синхронізації на ~log(N), де N — кількість реплік моделі. NoLoCo включає додаткові заходи для забезпечення того, щоб збіжність не сповільнювалась. Натхненний методами динамічної та випадкової маршрутизації з SWARM Parallelism та DiPaCo, NoLoCo випадковим чином маршрутизує навчальні дані між різними репліками етапів конвеєра.
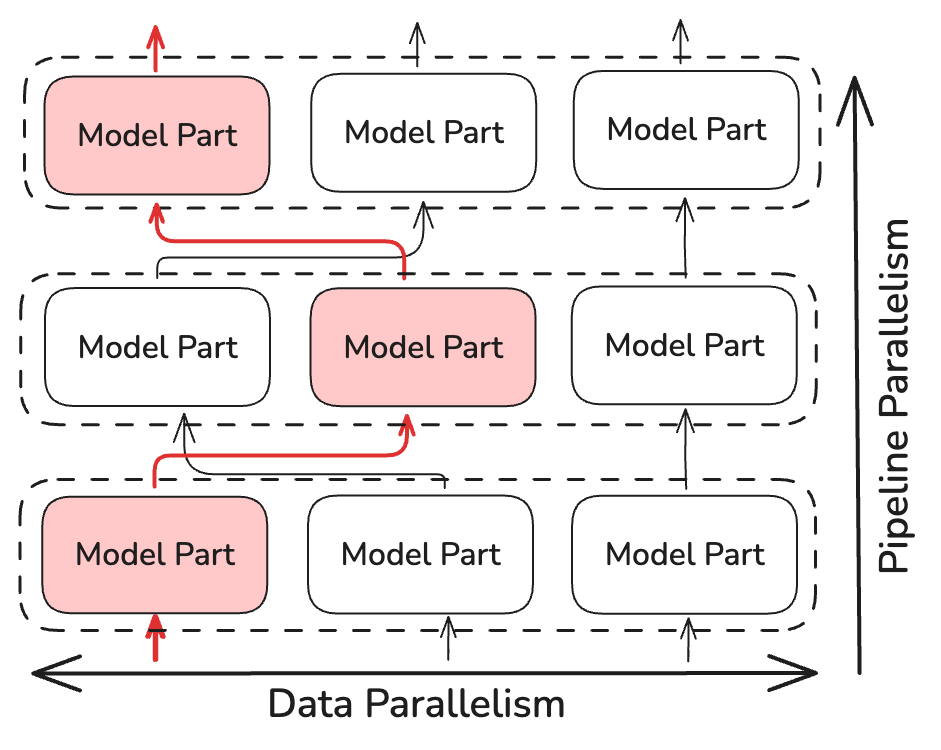
Це забезпечує достатнє перемішування градієнтів між даними, розподіленими по паралельних екземплярах.
NoLoCo також використовує новий варіант моменту Нестерова, в якому додається третій член для наближення ваг до один одного. З урахуванням додаткового члена повне вираження для моменту Нестерова стає:
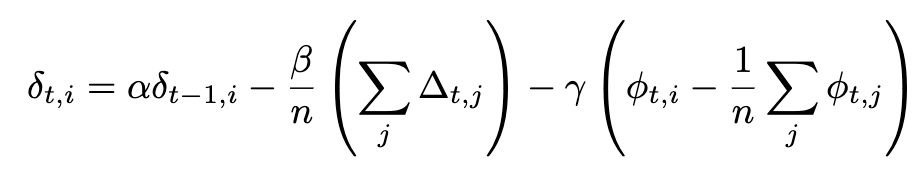
Якщо синхронізація застосовується до всіх робочих вузлів, останній член зникає, і ми відновлюємо початкове вираження моменту Нестерова, використаного в DiLoCo. Додаткові члени ілюструються на рисунку нижче:
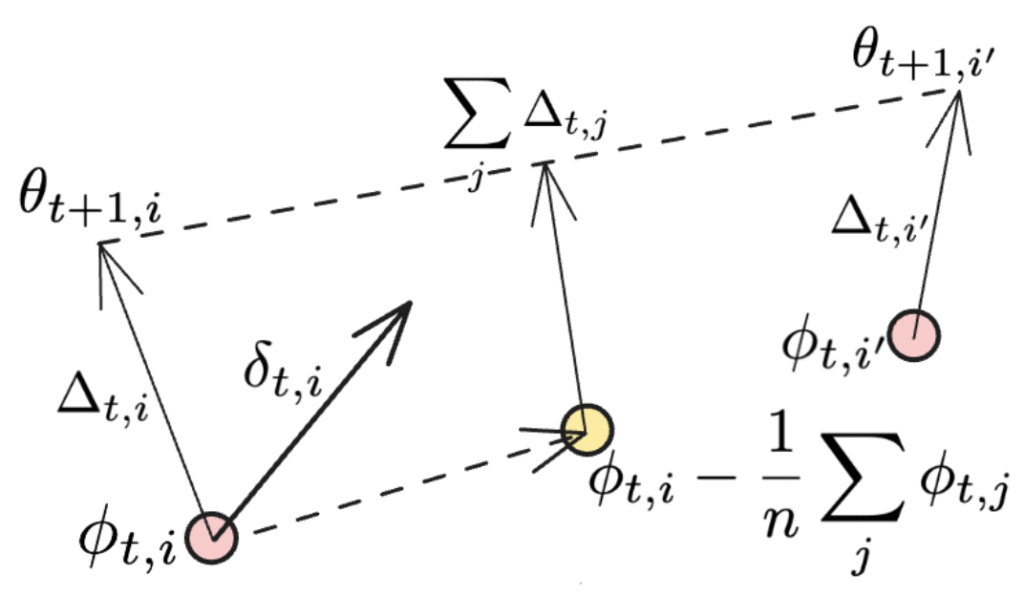
Другий термін представляє собою усереднення напрямку, де кожен індивідуальний робітник NoLoCo оновлює ваги, у той час як останній термін може бути розглянутий як ще одне оновлення, яке наближає ваги різних робітників до їх початкової позиції. Коли це виконується протягом кількох ітерацій, третій термін матиме схожий ефект з “катанням” усереднених вибірок ваг реплік у процесі навчання.
Простіше кажучи, NoLoCo включає наступні кроки:
- Локальна фаза. Кожна репліка виконує k оновлень методом стохастичного градієнтного спуску (SGD).
- Парне усереднення. Потім вона випадковим чином вибирає одного партнера і усереднює ваги, використовуючи правило Нестерова, яке обмежує дрейф.
- Випадкова маршрутизація. Протягом локальної фази активації передаються випадковим партнерським шарам, забезпечуючи неперервне змішування градієнтів.
Результати
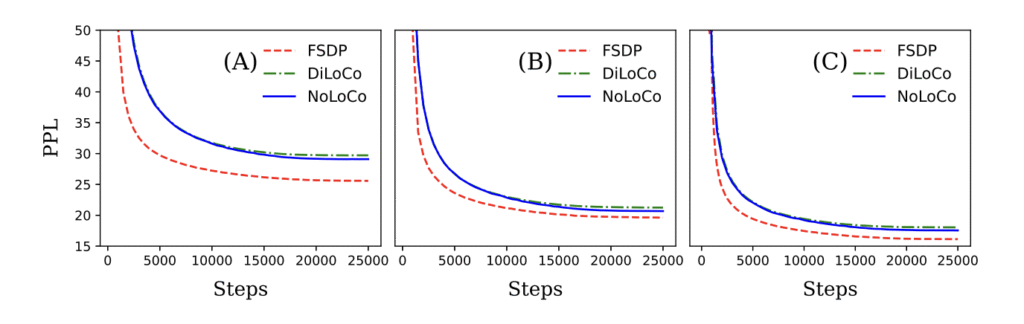
Ми продемонстрували як теоретично, так і емпірично, що NoLoCo зберігає збіжність, суттєво знижуючи вимоги до комунікацій. Використовуючи ці методи, NoLoCo ефективно навчає моделі від мільйонів до мільярдів параметрів. Наші експерименти з моделями в стилі Llama, що варіюються від 125 мільйонів до 6,8 мільярдів параметрів, з використанням до 1000 реплік, показують, що кроки синхронізації NoLoCo на порядок швидші, ніж в DiLoCo на практиці, і при цьому сходяться швидше. Більш того, як стратегія синхронізації, так і модифікований оптимізатор можуть бути безшовно інтегровані в інші протоколи навчання і архітектури моделей.
Чому це важливо
Видалення глобальної операції all-reduce знижує поріг інфраструктури для навчання великих моделей, дозволяючи дослідникам краще використовувати децентралізоване обладнання без спеціалізованих з’єднань. Ми раді представити NoLoCo як повністю відкрите рішення для просування меж відкритого машинного навчання.
Дізнатися більше
Вивчити репозиторій – бенчмарки, скрипти та мінімальна реалізація на 100 рядків.
Приєднуйтесь до обговорення на нашому Discord або слідкуйте за нами в X.