CheckFree: विफलताओं के लिए प्रशिक्षण बिना चेकपॉइंट्स के

यह एक अकादमिक शोध पत्र है जो चेकफ्री (CheckFree) का वर्णन करता है – एक नवीन पुनर्प्राप्ति विधि जो वितरित प्रशिक्षण (distributed training) में विफलताओं के लिए डिज़ाइन की गई है। यह विधि चेकपॉइंटिंग (checkpointing) या अतिरिक्त गणना (redundant computation) की आवश्यकता के बिना काम करती है, और लगातार विफलताओं की स्थिति में भी कुशल प्रशिक्षण (efficient training) सक्षम बनाती है।
मुख्य बिंदु
- पारंपरिक चेकपॉइंट्स के मुकाबले 1.6x तक त्वरित: CheckFree और CheckFree+ प्रशिक्षण समय को चेकपॉइंट्स के मुकाबले 1.6x तक तेज कर सकते हैं, जब प्रशिक्षण चरणों के दौरान अक्सर विफलताएँ होती हैं।
- चेकपॉइंट्स के बिना पुनर्प्राप्ति की नई विधि: CheckFree बिछड़े हुए चरण के वजन को उनके पड़ोसी चरणों के वजन का औसत लेकर पुनः प्राप्त करता है।
पूर्वापेक्षाएँ
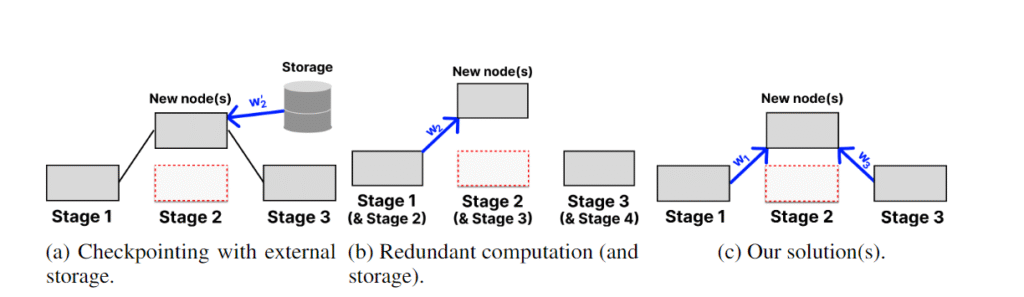
अत्याधुनिक पुनर्प्राप्ति रणनीतियों में, मॉडल वज़नों (weights) को गैर-त्रुटिपूर्ण केंद्रीकृत संग्रहण (non-faulty centralized storage) में चेकपॉइंट (periodically stored) किया जाता है। यह अत्यधिक खर्चीला साबित हो सकता है – उदाहरण के लिए, एक LLaMa 70B चेकपॉइंट को उच्च बैंडविड्थ कनेक्शन (500 Mb/s से अधिक) पर भी स्टोर करने में 20 मिनट से अधिक समय लगता है। जब कोई त्रुटि (fault) होती है, तो मॉडल को पूरी तरह से पिछले चेकपॉइंट पर वापस लौटा दिया जाता है, जिससे संभावित रूप से घंटों का प्रशिक्षण (training) नष्ट हो जाता है।
बैंबू (Bamboo) चेकपॉइंटिंग के विकल्प के रूप में अतिरिक्त गणना (redundant computation) का प्रस्ताव करता है – एक स्टेज के वज़नों को पिछली स्टेज पर संग्रहित करना और प्रत्येक माइक्रोबैच के फॉरवर्ड पास (forward pass) को अतिरिक्त प्रतियों पर क्रियान्वित करना। इस तरह, जब एक भी त्रुटि होती है, तो प्रशिक्षण तुरंत फिर से शुरू किया जा सकता है। हालाँकि, बड़े मॉडल्स के लिए यह विधि अप्रभावी साबित होती है, क्योंकि प्रत्येक नोड को अतिरिक्त परतों (redundant layers) को संग्रहित करने के लिए अपनी मेमोरी आवश्यकताओं को दोगुना करना पड़ता है।
चेकफ्री (CheckFree) और चेकफ्री+ (CheckFree+) बड़े पैमाने पर भौगोलिक रूप से वितरित प्रशिक्षण (geo-distributed training) में एक व्यवहार्य विकल्प प्रदान करते हैं, क्योंकि इनमें कोई अतिरिक्त गणना (computation) या संचार (communication) खर्च नहीं होता है।
यह कैसे काम करता है
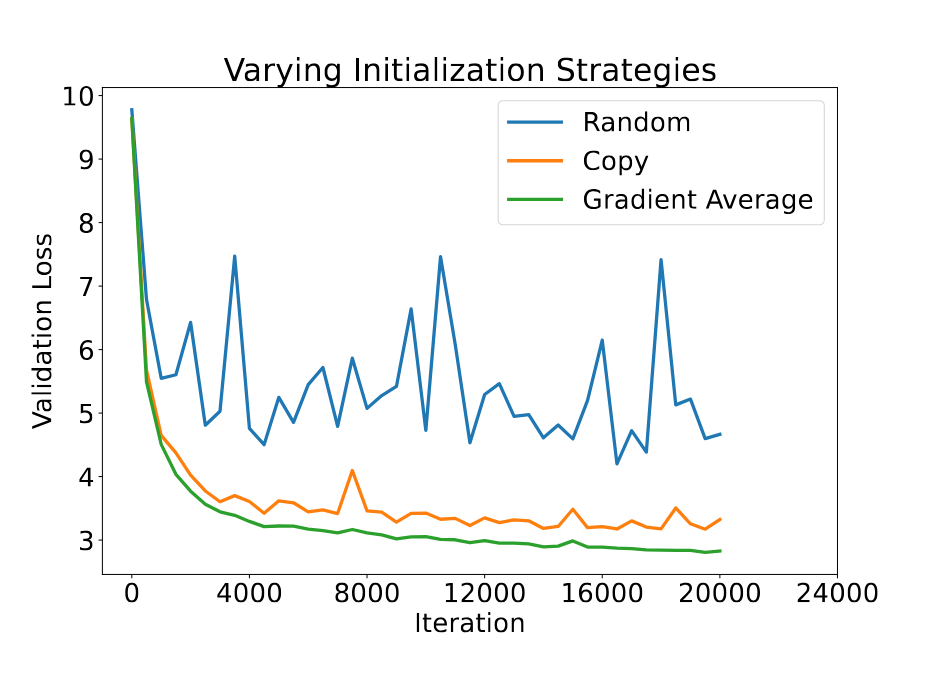
जब विफलता होती है, तो खोए हुए चरण को उसके दो पड़ोसी चरणों के वजन का औसत लेकर पुनर्प्राप्त किया जाता है। यह LLM में स्तरों के प्राकृतिक अतिरिक्तता का उपयोग करता है, जैसा कि पहले के कार्यों में दिखाया गया था, जहाँ कुछ स्तरों को हटाने से मॉडल के प्रदर्शन पर कोई महत्वपूर्ण प्रभाव नहीं पड़ता। हम अनुभवजन्य रूप से यह दिखाते हैं कि औसत निकालना सामान्यतः स्टैकिंग लेयर विधियों में उपयोग किए गए सीधे कॉपी करने से काफी बेहतर होता है।
औसत निकालने का एक सरल तरीका दो चरणों का समान रूप से औसत निकालना है। हालांकि, यह औसत निकालना चरणों की महत्वता और संकेंद्रण का भेद नहीं करता, जिससे मॉडल के संकेंद्रण की गति धीमी हो जाती है। इसलिए, CheckFree उस चरण के अंतिम ग्रेडिएंट नॉर्म के वजन का उपयोग करता है। यह अवधारणात्मक रूप से उन चरणों को अधिक वजन देता है जो अभी तक संकेंद्रित नहीं हुए हैं, और आंशिक रूप से उनके कार्यात्मकता को नए चरण पर स्थानांतरित करता है। यह सुनिश्चित करने के लिए कि नया पुनः प्रारंभित चरण “कमी पूरी करे”, CheckFree पुनर्प्राप्ति के बाद कुछ कदमों तक लर्निंग दर को बढ़ाता है।
हालाँकि, यह रणनीति पहले और अंतिम चरणों के वजन को पुनः प्राप्त नहीं कर सकती, क्योंकि उनके पास औसत निकालने के लिए कोई पड़ोसी चरण नहीं होते। इसके लिए हम CheckFree+ का प्रस्ताव करते हैं। यह आउट-ऑफ-ऑर्डर निष्पादन का उपयोग करके अंतिम चरणों को पुनः प्राप्त करने की अनुमति देता है: हर दूसरे पैकेट पहले दो और अंतिम दो चरणों के क्रम को बदलता है, जिससे मध्यवर्ती स्तरों को अपने पड़ोसी स्तरों के व्यवहार को अध्ययन करने का अवसर मिलता है, जैसे अतिरिक्त गणनाएँ, लेकिन बिना अतिरिक्त मेमोरी या गणना ओवरहेड के। विफलता के मामले में “अतिरिक्त” चरणों को अनुपलब्ध चरणों की जगह पर कॉपी किया जा सकता है।
परिणाम
हमने CheckFree और CheckFree+ का परीक्षण किया है, विफलताओं की दर 5% से 16% प्रति घंटे तक, पारंपरिक चेकपॉइंट्स और अतिरिक्त गणनाओं की तुलना में। हम देखते हैं कि विभिन्न मॉडल आकारों पर, CheckFree और CheckFree+ आधुनिक तरीकों की तुलना में वास्तविक प्रशिक्षण समय में तेजी से संकेंद्रित हो सकते हैं। हालांकि, हमारे तरीके बुनियादी लाइन के मुकाबले संकेंद्रण को कम करते हैं (जो अतिरिक्त गणनाओं के बराबर होता है)। लेकिन अपनी हल्की पुनर्प्राप्ति प्रक्रिया के कारण, CheckFree और CheckFree+ अधिक उच्च थ्रूपुट प्राप्त कर सकते हैं, जिससे ये बड़े भाषा मॉडलों के वितरित प्रशिक्षण के लिए आदर्श बन जाते हैं।
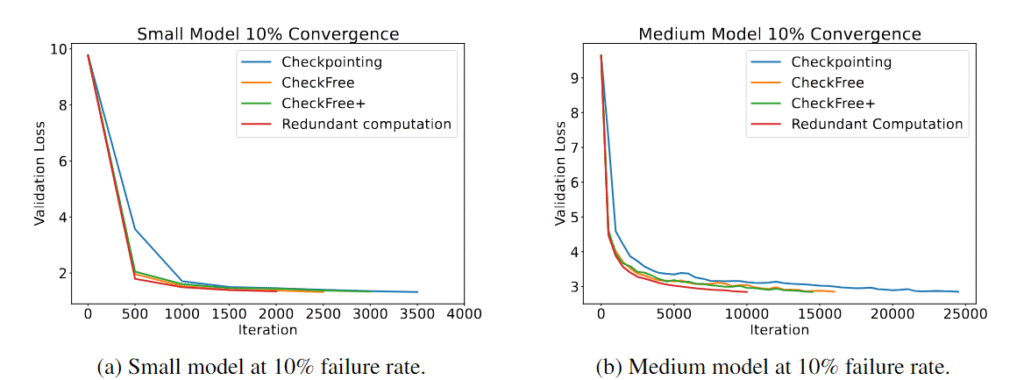
यह क्यों महत्वपूर्ण है
विकेन्द्रीकृत लर्निंग में, नोड्स कभी भी नेटवर्क से जुड़ सकते हैं या बाहर जा सकते हैं, जिससे पूरे चरण का विफल हो जाना संभव हो सकता है। यहां तक कि विरासत के उदाहरणों पर वितरित लर्निंग में भी, एक पूरा चरण खो सकता है यदि संबंधित नोड्स एक ही क्षेत्र में नियोजित हैं। चेकपॉइंट्स बार-बार पुनः आरंभ होने के कारण उच्च ओवरहेड बना सकते हैं, जबकि अतिरिक्त गणनाएँ बड़े मॉडल्स के लिए असंभव हो सकती हैं क्योंकि यह मेमोरी की आवश्यकता को रैखिक रूप से बढ़ा देती है। CheckFree बिना अतिरिक्त गणनाओं या संचार के LLM की लर्निंग को पुनः प्राप्त करने का एक प्रभावी तरीका प्रदान करता है।
और अधिक जानें
- लेख पढ़ें
- रिपॉजिटरी का अध्ययन करें
- चर्चा में शामिल हों: Discord · X