NoLoCo:无需 All-Reduce 的大模型训练

这篇学术文章介绍了 NoLoCo,一种新的分布式学习优化方法,它通过采用 gossip 方法替代全局同步步骤,使得在低带宽的异构网络中进行训练成为可能。
现代的大模型训练方法要求节点之间频繁交换梯度,这需要高速、低延迟的连接。否则,节点将在等待更新时处于空闲状态。此前提出的方法,如 DiLoCo,通过减少 all-reduce 的频率来降低通信成本,但每次事件仍然涉及每个副本,因此仍然继承了延迟的限制。
今天,我们通过 NoLoCo 拓展了这一研究方向——NoLoCo 完全排除了全局的 all-reduce 步骤。在短的本地 SGD 更新后,副本与一个随机副本进行加权平均,同时激活随机地在流水线阶段之间转发。使用了修改版的 Nesterov 步骤来保持参数的一致性。在使用最多 1000 个通过互联网连接的 GPU 进行的实验中,NoLoCo 在验证集上的准确度与标准数据并行性相同,同时将同步延迟减少了大约 10 倍。
关键亮点
- 无需 All-reduce
NoLoCo 使用数据并行,但排除了全局同步(all-reduce),仅在 小规模的副本对之间 交换数据。 - 不损失收敛速度
通过随机路由流水线阶段之间的激活以及在 Nesterov 动量中添加特殊项来减少副本之间的离散,从而保持了较快的收敛。 - 在大规模下同步速度提高 10 倍
在 1000 个副本的情况下,NoLoCo 保持了基线的准确度,并加速了每次同步步骤,相比于树状 all-reduce。
基本原理
在标准的数据并行训练中,每个工作节点在自己的小批次上计算梯度,然后参与集群操作 all-reduce,使每个副本获得相同的更新。集体通信随着副本数量线性扩展,并且受最慢连接的限制。在通过互联网连接的节点上,这一步骤主导了执行时间并消耗了计算资源。低通信方案,如 DiLoCo,通过减少执行 all-reduce 的频率来降低通信成本,但每次同步仍然涉及到每个工作节点,导致相同的延迟限制。
NoLoCo 展示了我们可以避免这一步骤而不降低收敛性。
工作原理
NoLoCo 并不执行 all-reduce 操作,而是仅同步少量的随机选择副本(至少两个)。这将同步时间的复杂度降低到 ~log(N),其中 N 是模型的副本数量。NoLoCo 还采取了额外的措施来确保收敛性不减慢。受 SWARM 并行化 和 DiPaCo 方法的启发,NoLoCo 随机路由训练数据在流水线阶段之间的不同副本。
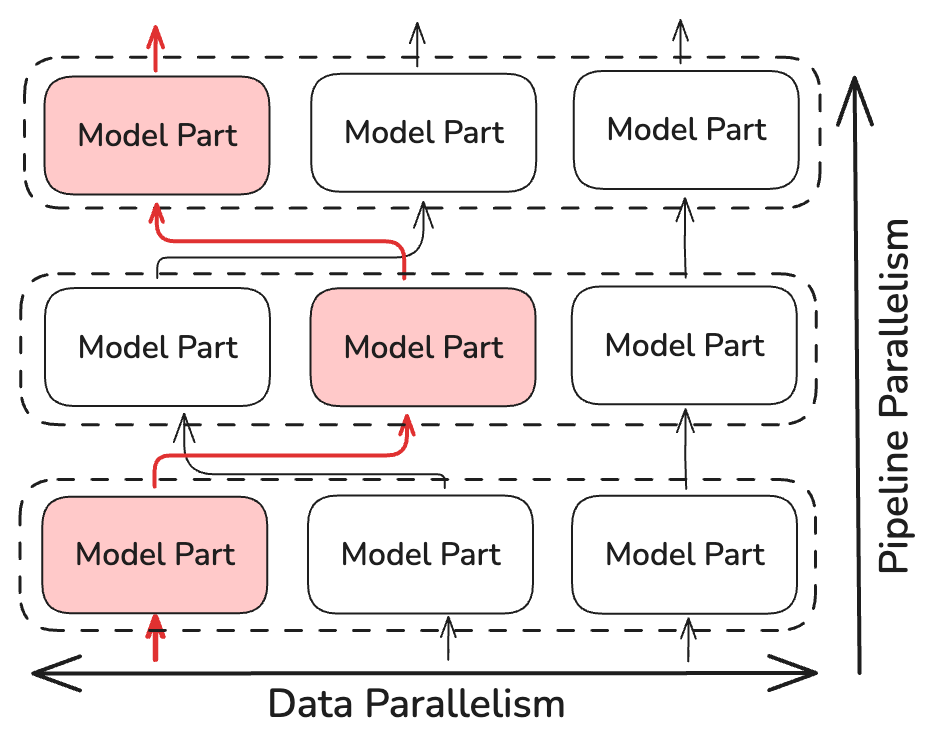
这确保了在并行实例间的数据梯度得到充分混合。
NoLoCo 还使用了修改版的 Nesterov 动量,其中添加了第三项来将副本权重拉近。考虑到额外的项,Nesterov 动量的完整表达式变为:
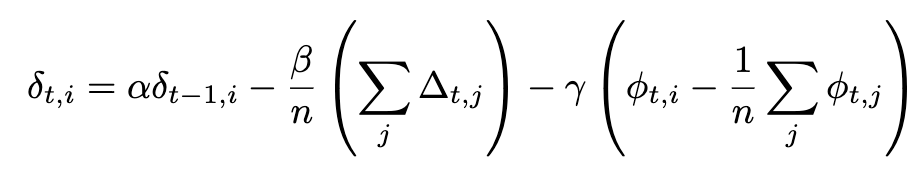
当同步应用于所有工作节点时,最后一项消失,我们恢复了 DiLoCo 中使用的原始 Nesterov 动量表达式。附加项在下图中进行了说明:
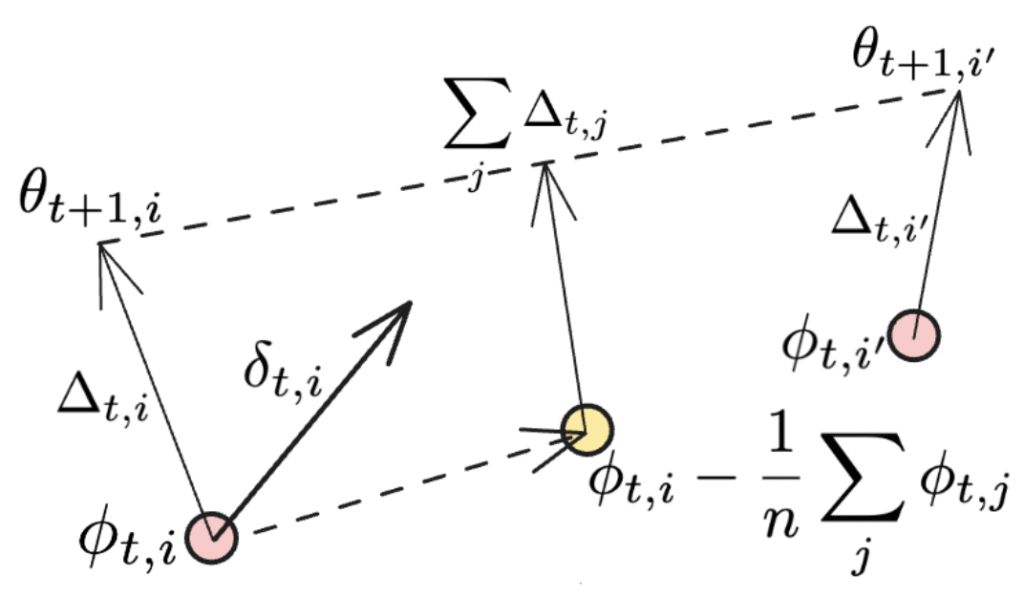
第二项代表方向的平均值,每个 NoLoCo 工作节点更新权重,而最后一项可以被视为另一个更新,它将不同工作节点的权重推向它们的原始位置。当这一过程在多次迭代中进行时,第三项的效果类似于“滚动”在训练过程中平均的副本权重。
简单来说,NoLoCo 包含以下步骤:
- 本地阶段:每个副本使用随机梯度下降(SGD)进行 k 次更新。
- 配对加权平均:然后它随机选择一个伙伴,并使用 Nesterov 规则进行加权平均,从而限制漂移。
- 随机路由:在本地阶段,激活在不同的配对副本之间传递,确保梯度的连续混合。
结果
我们在实验中展示了,无论是理论上还是实证上,NoLoCo 都能保持收敛性,同时大幅降低通信需求。通过这些方法,NoLoCo 有效地训练了从百万到十亿参数的模型。我们在类似 Llama 的模型上的实验,模型参数从 1.25 亿到 68 亿不等,使用最多 1000 个副本,结果显示,NoLoCo 的同步步骤在实际操作中比 DiLoCo 快几个数量级,同时收敛速度更快。此外,作为同步策略,NoLoCo 的优化器和修改后的优化器可以无缝集成到其他学习协议和模型架构中。

为什么这很重要
全局 all-reduce 操作的去除降低了大模型训练的基础设施门槛,使研究人员能够更好地利用去中心化的设备,而无需依赖专用连接。我们很高兴能以完全开放的方式介绍 NoLoCo,以推动开放机器学习的边界。
了解更多
探索代码库 — 基准测试、脚本和 100 行的最小实现。