RL Swarm: 강화 학습 협업을 위한 프레임워크

이것은 인터넷을 통해 협력적 강화 학습을 수행하는 P2P(피어-투-피어) 노드를 위한 오픈 소스 코드(MIT 라이선스)이며, 소비자용 또는 데이터센터용 하드웨어를 사용하는 누구나 접근할 수 있습니다.
우리는 오랫동안 믿어왔습니다, 머신 러닝의 미래는 분산되고 분할된 형태가 될 것이라고. 현재의 모노리식 모델은 전 세계 각 장치에서 존재하는 분할된 파라미터로 대체될 것입니다. 우리의 연구는 이러한 미래로 가는 다양한 경로를 탐구하고 있으며, 최근 강화 학습(RL)은 모델들이 서로 소통하고 답변을 비판하는 공동 학습을 통해 특히 효과적으로 학습한다는 사실을 발견했습니다.
우리는 RL 모델들이 개별적으로 학습하는 것보다 집단 커뮤니티로 학습할 때 더 빠르게 학습한다는 결론에 도달했습니다. 기술적인 세부 사항은 여기에서 확인하거나, 라이브 데모에 참여하여 기술을 실제로 경험해 보세요.
작동 방식
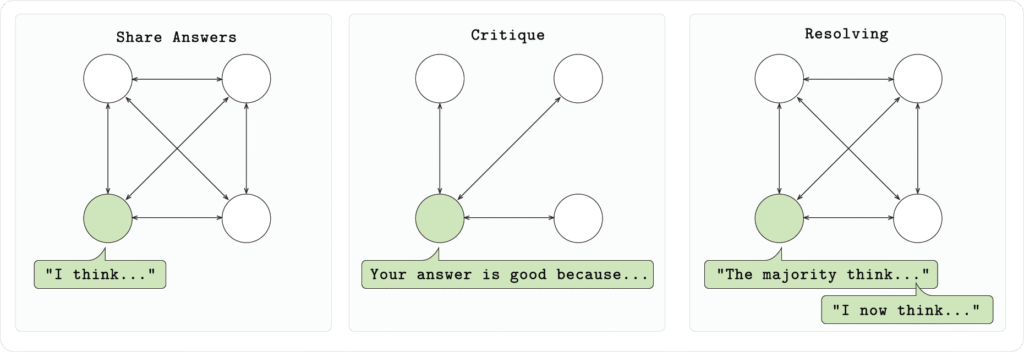
우리의 설정에서는 커뮤니티 내의 각 노드가 Qwen 2.5 1.5B 모델을 실행하고, (GSM8K) 수학 문제를 세 단계로 해결합니다:
- 1단계 (답변):
각 모델은 문제를 독립적으로 해결하고, 지정된 형식에 맞춰 추론과 답변을 제시합니다. - 2단계 (비판):
각 모델은 다른 모델들이 제공한 답변을 고려하고 피드백을 제공합니다. - 3단계 (결정):
각 모델은 각 질문에 대해 가장 좋은 답을 투표합니다. 그런 다음 각 모델은 최종 수정된 답변을 제공합니다.
우리의 실험에서 우리는 이 시스템이 학습을 가속화하여 모델들이 보지 못한 테스트 데이터에서 더 적은 학습 단계로 더 정확한 답을 제공한다는 사실을 발견했습니다.

위의 플롯은 스웜 내 하나의 노드에서 얻은 Tensorboard 결과를 보여줍니다. 각 플롯에서 다단계 게임 라운드 간 “재설정”에 따른 주기적 동작을 확인할 수 있습니다. 모든 플롯의 x축은 스웜 참여 후 경과 시간을 나타냅니다. y축은 왼쪽부터 오른쪽으로 다음과 같습니다:
i) “합의 정확성 보상”: 스웜 참가자가 최적 답안 선택을 올바르게 형식화하고 선택한 답안이 수학적으로 정확했을 때 부여
ii) 총 보상: 여러 규칙 기반 보상의 가중 합 (예: 응답의 형식 및 수학적/논리적 정확성 검사)
iii) 훈련 손실: 보상 최대화를 위한 피드백 신호로, “기본” LLM 업데이트에 전파됨
iv) 모델의 응답 완성 길이: 출력 응답의 토큰 수를 capture (이는 모델이 동료들의 critique을 받을 때 더 간결해지는 것을 학습함을 보여줍니다)
커뮤니티에 참여하기
이 시스템을 데모하고 실험을 확장하기 위해, 우리는 라이브 데모를 출시하며, 누구나 참여할 수 있습니다. 이는 인터넷을 통해 RL 학습 커뮤니티를 구축하기 위한 완전 오픈 시스템입니다.
swarm-node를 실행하면 새 로이 클러스터를 만들거나 기존 노드에 공개 주소를 사용하여 연결할 수 있습니다. 각 클러스터는 강화 학습(RL)을 집단적으로 수행하며, 모델을 공동으로 개선하기 위해 Hivemind 기반의 스와핑 시스템을 적용합니다.
내장 클라이언트를 실행하면 클러스터에 연결하여 메시지를 받고, 자신의 모델을 로컬에서 학습할 수 있습니다. 앞으로 우리는 로이 시스템을 위한 더 많은 실험을 시작할 예정이며, 커뮤니티의 광범위한 참여를 환영합니다.
***
RL Swarm은 머신 러닝의 미래를 엿볼 수 있는 시스템입니다. 그것은 참가자들 간의 공동 RL을 위한 프레임워크 시스템을 제공하며, 여기서 지능은 제한된 폐쇄 실험실의 지혜 대신 집단 지혜를 사용합니다. 확장은 전 세계 모든 장치를 연결하는 개방형 계산 네트워크가 필요할 것입니다. 더 많은 세부 사항은 곧 공개됩니다.