RL Swarm: إطار للتعلم التعزيزي التعاوني

هذا رمز مفتوح المصدر (برخصة MIT) لعُقَد الند-للند التي تقوم بالتعلّم التعاوني المعزّز عبر الإنترنت، وهو متاح لأي شخص باستخدام أجهزة المستهلكين أو أجهزة مراكز البيانات.
نحن منذ وقت طويل نؤمن بأن مستقبل التعلم الآلي سيكون لامركزيًا ومجزأً. ستُستبدل نماذجنا الحالية الضخمة بمعاملات موزعة موجودة على كل جهاز حول العالم. في أبحاثنا نستكشف مسارات مختلفة تؤدي إلى هذا المستقبل، ومؤخرًا وجدنا أن التعلم التعزيزي (RL) يعمل بكفاءة خاصة عندما تُدرَّب النماذج معًا، متواصلة مع بعضها البعض وناقدة لإجابات بعضها.
توصلنا إلى أن نماذج RL تتعلم أسرع عندما تُدرَّب كجماعة تعاونية، لا منفردة.
اقرأ تفاصيل الآلية هنا أو انضم إلى عرض حي لرؤية التقنية قيد العمل.
كيف يعمل
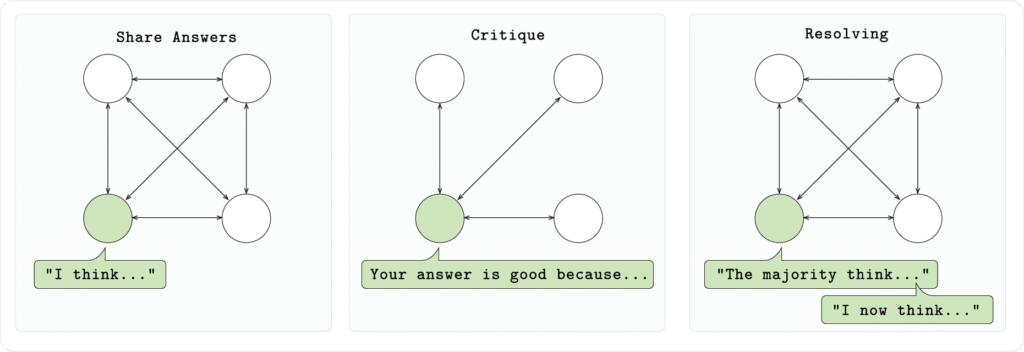
في إعدادنا، كل عقدة في المجتمع تشغّل نموذج Qwen 2.5 1.5B وتحل مسائل رياضية (GSM8K) عبر ثلاث مراحل:
- المرحلة 1 (الإجابة):
كل نموذج يحل المسألة بشكل مستقل، مُخرجًا تفكيره وإجابته بالتنسيق المطلوب. - المرحلة 2 (النقد):
كل نموذج يراجع الإجابات المقدمة من النماذج الأخرى ويعطي ملاحظاته. - المرحلة 3 (الحسم):
كل نموذج يصوّت على أفضل إجابة لكل سؤال. بعد ذلك يقدم كل نموذج إجابته النهائية المنقحة.
في تجاربنا اكتشفنا أن هذا النظام يسرّع عملية التعلم، مما يمكّن النماذج من إعطاء إجابات أدق على بيانات اختبار غير مرئية بعدد خطوات تدريب أقل.

تُظهر الرسوم البيانية أعلاه نتائج Tensorboard من عقدة في السرب. في كل رسم بياني، نلاحظ سلوكًا دوريًا ناتجًا عن “عمليات إعادة الضبط” بين جولات اللعبة متعددة المراحل. تحتوي جميع الرسوم البيانية على الوقت منذ الانضمام إلى السرب كمحور أفقي (x). بالنسبة للمحور الرأسي (y)، ومن الرسم البياني الأيسر إلى الأيمن، نرى:
i) “مكافأة صحة الإجماع”، التي تسجل عندما قام مشارك السرب هذا بتنسيق خياراته للإجابة الأفضل بشكل صحيح وكانت إجابته المختارة صحيحة رياضياً؛
ii) المكافأة الإجمالية، وهي مجموع مرجح للعديد من المكافآت القائمة على القواعد (مثل التحقق من التنسيق والصحة الرياضية/المنطقية للاستجابات)؛
iii) فقدان التدريب، الذي يسجل إشارة التغذية الراجعة لتعظيم المكافأة التي يتم نقلها لتحديث نموذج اللغة الأساسي (LLM)؛
iv) طول اكتمال الاستجابة للنموذج، الذي يسجل عدد الرموز (tokens) في الاستجابة الناتجة (وهذا يظهر أن النماذج تتعلم أن تكون أكثر إيجازًا عندما يتم تقييمها من قبل أقرانها).
الانضمام إلى المجتمع
لتجريب هذا النظام وتوسيع نطاق التجارب، أطلقنا عرضًا حيًا يمكن لأي مستخدم الانضمام إليه. إنها منظومة مفتوحة بالكامل لإنشاء مجتمعات تدريب RL عبر الإنترنت.
تشغيل swarm-node يتيح لك إنشاء سرب جديد أو الاتصال بعقدة قائمة باستخدام عنوانها العام. كل سرب ينفذ التعلم التعزيزي القائم على الحجج بشكل جماعي، باستخدام نظام تبادل الإشاعات المبني على Hivemind لتحسين النماذج بشكل مشترك.
تشغيل العميل المدمج يتيح لك الانضمام إلى السرب، استلام الرسائل، وتدريب نموذجك محليًا كجزء من الجماعة. في المستقبل سنطلق المزيد من التجارب للسرب، ونسعد بمشاركة المجتمع على نطاق واسع.
انضم إلى “السرب”
التقرير التقني
***
RL Swarm — هو نظرة إلى مستقبل التعلم الآلي. إنه يقدم إطارًا للتعلم التعزيزي التعاوني بين المشاركين، حيث يستخدم الذكاء الحكمة الجماعية بدلًا من دائرة ضيقة من المختبرات المغلقة. التوسع سيتطلب شبكة حوسبة مفتوحة تصل كل جهاز في العالم. التفاصيل — قريبًا.