NoLoCo: تدريب النماذج الكبيرة بدون all-reduce

هذه مقالة علمية تصف NoLoCo، أسلوبًا جديدًا لتحسين التدريب الموزع، يستبدل خطوة المزامنة العالمية بطريقة gossip، مما يسمح بالتدريب في الشبكات غير المتجانسة ومنخفضة النطاق الترددي.
الأساليب الحديثة لتدريب النماذج الكبيرة تتطلب تبادلًا متكررًا للتدرجات بين العقد، مما يتطلب اتصالات عالية السرعة ومنخفضة الكمون. بخلاف ذلك تبقى العقد خاملة في انتظار التحديثات. الأساليب السابقة مثل DiLoCo تقلل تكلفة الاتصال عبر تقليل تكرار all-reduce، لكن كل عملية تزامن تشمل جميع النسخ وبالتالي ترث نفس قيود الكمون.
اليوم نوسّع هذا المجال البحثي عبر NoLoCo — أسلوب يلغي تمامًا خطوة all-reduce العالمية. بعد عدد قصير من تحديثات SGD المحلية، تقوم النسخ بمزامنة الأوزان مع نسخة عشوائية واحدة، بينما تُعاد توجيه التفعيلات (activations) عشوائيًا بين مراحل خط الأنابيب. يُستخدم تعديل لخطوة Nesterov للحفاظ على اتساق المعاملات. في التجارب باستخدام ما يصل إلى 1000 GPU متصلة عبر الإنترنت، يحقق NoLoCo نفس دقة التحقق (validation accuracy) كالتوازي التقليدي للبيانات، مع تقليل زمن المزامنة بمقدار 10 مرات تقريبًا.
يسلط الضوء على
- No all-reduce
يطبق NoLoCo data-parallelism، لكنه يزيل المزامنة العالمية (all-reduce)، متبادلًا البيانات فقط بين أزواج صغيرة من العقد. - No loss in convergence speed
يتم تقليل التباين بين النسخ عبر التوجيه العشوائي للتفعيلات بين مراحل خط الأنابيب، وإضافة خاصة إلى Nesterov momentum تتحكم في انجراف الأوزان. - 10× faster synchronisation at scale
عند 1,000 نسخة يحافظ NoLoCo على دقة baseline، مع تسريع كل خطوة مزامنة مقارنةً بـ tree all-reduce.
الأساسيات
في التدريب القياسي بالتوازي عبر البيانات، كل عقدة عاملة تحسب التدرجات على mini-batch محلي، ثم تشارك في عملية all-reduce على مستوى الكتلة بحيث تحصل كل نسخة على نفس التحديث. الاتصال الجماعي يتدرج خطيًا مع عدد النسخ ويُقيّد بأبطأ وصلة. على العقد المتصلة عبر الإنترنت، هذه الخطوة تهيمن على زمن التنفيذ وتُهدر موارد الحساب. المخططات منخفضة الاتصال مثل DiLoCo تقلل تكرار all-reduce، لكنها تظل تشمل جميع العقد في كل مزامنة، مما يؤدي لنفس قيود الكمون.
يوضح NoLoCo أننا يمكن أن نتجنب هذه المزامنة all-reduce دون التأثير على التقارب.
كيف يعمل
بدلًا من تنفيذ all-reduce، يزامن NoLoCo فقط نسخًا صغيرة يتم اختيارها عشوائيًا (اثنتان على الأقل). هذا يقلل تعقيد زمن المزامنة إلى ~log(N)، حيث N هو عدد النسخ. يتضمن NoLoCo تدابير إضافية لضمان عدم تباطؤ التقارب. مستلهمًا من أساليب التوجيه الديناميكي والعشوائي من SWARM Parallelism وDiPaCo، يقوم NoLoCo بتوجيه بيانات التدريب عشوائيًا بين نسخ مختلفة من مراحل خط الأنابيب.
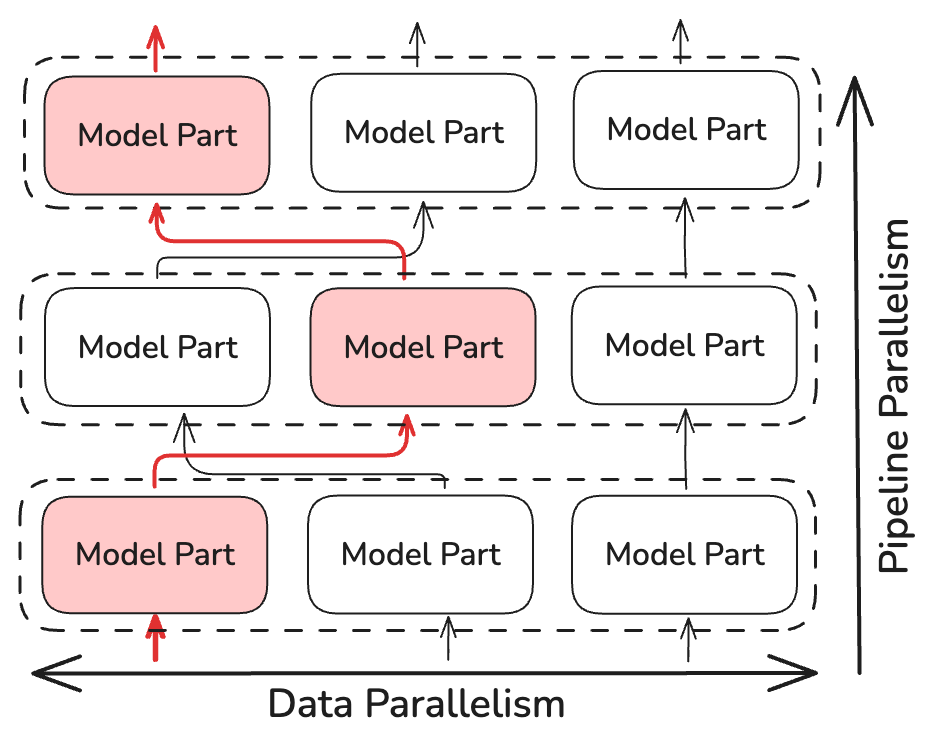
هذا يضمن خلطًا كافيًا للتدرجات بين البيانات الموزعة عبر النسخ المتوازية.
كما يستخدم NoLoCo نسخة جديدة من Nesterov momentum، حيث يُضاف حد ثالث لتقريب الأوزان من بعضها. مع هذا الحد الإضافي يصبح التعبير الكامل لـ Nesterov كما يلي:
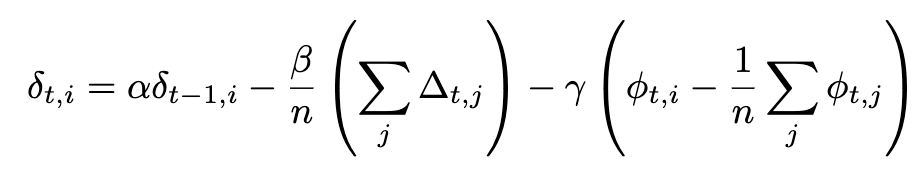
إذا طُبقت المزامنة على جميع العقد، يختفي الحد الأخير ونستعيد التعبير الأصلي المستخدم في DiLoCo. توضح الحدود الإضافية في الشكل أدناه:
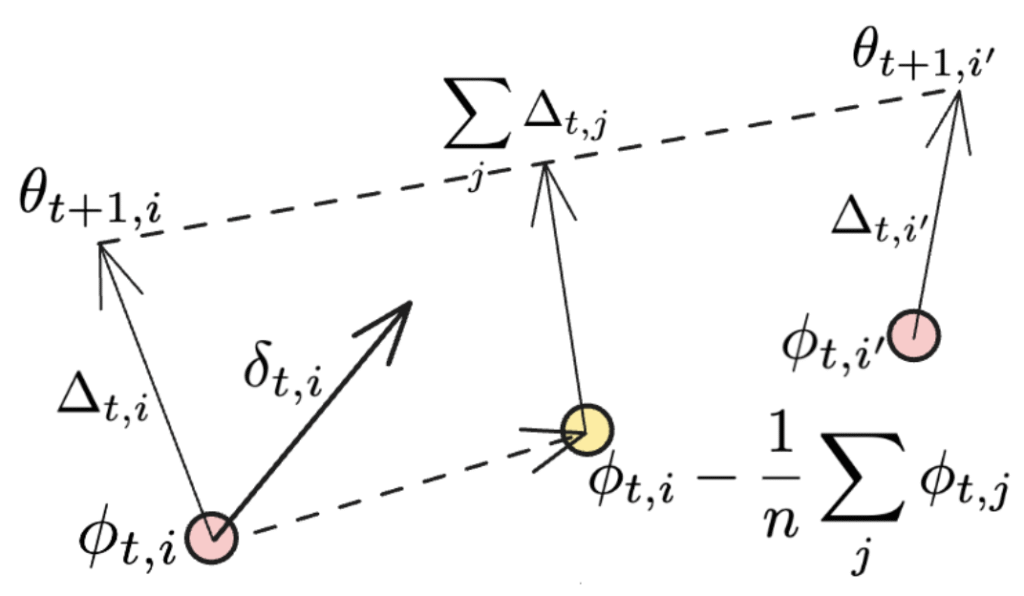
الحد الثاني يمثل متوسط الاتجاه حيث يقوم كل عامل NoLoCo بتحديث الأوزان، بينما يمكن اعتبار الحد الأخير تحديثًا إضافيًا يقرب أوزان العاملين المختلفين نحو موقعهم الأصلي. عند تكراره على عدة دورات، يكون للحد الثالث تأثير مشابه لـ “تدوير” متوسطات أوزان النسخ أثناء التدريب.
ببساطة، يشمل NoLoCo الخطوات التالية:
- المرحلة المحلية. كل نسخة تقوم بـ k تحديثات باستخدام SGD.
- المتوسط الزوجي. تختار بعدها شريكًا عشوائيًا وتقوم بمزامنة الأوزان باستخدام قاعدة Nesterov التي تحد من الانجراف.
- التوجيه العشوائي. أثناء المرحلة المحلية، تُمرَّر التفعيلات إلى شركاء عشوائيين، مما يضمن استمرار خلط التدرجات.
النتائج
أظهرنا نظريًا وتجريبيًا أن NoLoCo يحافظ على التقارب مع تقليل كبير لمتطلبات الاتصال. باستخدام هذه الأساليب، يدرب NoLoCo النماذج بكفاءة بدءًا من ملايين وحتى مليارات المعاملات. تجاربنا مع نماذج على طراز Llama، تتراوح من 125 مليونًا إلى 6.8 مليار معامل، ومع ما يصل إلى 1000 نسخة، تُظهر أن خطوات المزامنة في NoLoCo أسرع بمرتبة كاملة من DiLoCo عمليًا، ومع ذلك تتقارب أسرع. علاوة على ذلك، يمكن دمج كل من استراتيجية المزامنة والمُحسّن المعدل بسلاسة في بروتوكولات تدريب أخرى وهندسات النماذج.

لماذا هذا مهم
إزالة عملية all-reduce العالمية تخفض حاجز البنية التحتية لتدريب النماذج الكبيرة، مما يسمح للباحثين باستخدام الأجهزة اللامركزية بشكل أفضل دون الحاجة إلى وصلات متخصصة. نحن متحمسون لتقديم NoLoCo كحل مفتوح بالكامل لدفع حدود التعلم الآلي المفتوح.
تعرّف أكثر
- اقرأ المقال
- استكشف المستودع – بنشماركات، سكربتات، وتنفيذ مرجعي بحدود 100 سطر.