SkipPipe: أسلوب اتصال فعّال للتعلم اللامركزي

هذه مقالة علمية حول الاتصال الفعّال أثناء التدريب المتوازي عبر خطوط الأنابيب (pipeline). يتم فيها تقديم خوارزمية جدولة مثالية تزيد من الأداء والقدرة على تحمل الأعطال، مع تقليل التأثير على التقارب (convergence) الناتج عن تخطي الطبقات. هذا يقلل زمن التكرارات في التدريب الموزع بنسبة تصل إلى 55% ويضمن تحملًا لأعطال العقد بنسبة 50% أثناء الاستدلال.
الإنجازات الحديثة في مجال النماذج اللغوية الكبيرة نتجت عن التوسع في الحجم. مجموعات البيانات الأكبر وعدد المعاملات الأعلى قادت إلى إنشاء نماذج أفضل. رغم أن هذا الاتجاه أظهر تحسنًا متوقعًا في الأداء، إلا أنه أدى أيضًا إلى زيادة التكاليف إلى الحد الأقصى، حيث أصبح من الضروري الآن توزيع النماذج عبر آلاف العقد الباهظة والمترابطة أثناء التدريب.
لحل هذه المشكلة، هناك حاجة إلى أساليب جديدة تحد من الاتصال بين العقد أثناء التدريب. هذا يفتح إمكانية التدريب على أجهزة موزعة جغرافيًا، مما يزيل عنق الزجاجة الأساسي في البنية التحتية الحالية.
معظم الأبحاث المبكرة في هذا المجال ركزت على أساليب توازي البيانات، حيث يقوم كل عقدة بتدريب نسخة مستقلة من النموذج ومشاركة تحديثات التدرجات على فترات متباعدة. هذه الأساليب تمثل نقطة انطلاق جيدة لأنها فعّالة اتصاليًا بطبيعتها. ومع ذلك، فهي لا تتوسع جيدًا، لأنها تتطلب من كل عقدة تخزين النموذج بالكامل في الذاكرة، مما يقيّد حجم النموذج بسعة ذاكرة أصغر عقدة مشاركة.
تقديم SkipPipe
بالتعاون مع باحثين من جامعة نوشاتيل (Neuchâtel) وجامعة دلفت التقنية طورنا SkipPipe — أسلوب تدريب متوازي عبر خطوط الأنابيب يتمتع بالقدرة على تحمل الأعطال، حيث يقوم بتخطي المراحل وإعادة توزيعها ديناميكيًا لتحسين التدريب في البيئات اللامركزية. SkipPipe يُظهر تقليصًا في وقت التدريب بنسبة 55% مقارنة بالأساليب القياسية في هذه البيئات، دون التأثير على التقارب.
كما يتمتع بمستوى عالٍ من تحمل الأعطال — حيث يحقق قدرة تحمل تصل إلى 50% من أعطال العقد مع خسارة لا تتجاوز 7% في مقياس perplexity أثناء الاستدلال (أي عندما تصبح نصف عقد خط الأنابيب لنموذج واحد غير متاحة، نخسر فقط 7% من perplexity عند تشغيل الاستدلال على النموذج المتناثر الناتج).
على عكس أساليب توازي البيانات التقليدية، يمكن لـ SkipPipe تدريب نماذج كبيرة. وبما أنه يقسم النموذج نفسه بين العقد، وليس فقط مجموعة البيانات، فإنه يقلل استهلاك الذاكرة على كل عقدة منفردة، ويزيل القيد على حجم النموذج، مما يسمح ببناء نماذج بحجم نظري غير محدود على بنية تحتية موزعة ولامركزية.
كيف يعمل
يعتمد SkipPipe على توازي خطوط الأنابيب التقليدي، لكنه يختار ديناميكيًا أي مراحل يتم تنفيذها لكل micro-batch، بدلًا من معالجة جميع المراحل بالتسلسل. في الخطوط التقليدية، يمر كل micro-batch عبر جميع طبقات النموذج، ما يعني أنه إذا تأخر أحد المراحل، يجب على جميع المراحل التالية الانتظار. SkipPipe يسمح بتحديد معامل تخطي (k%)، مما يمكّن من تجاوز بعض الطبقات لدفعة مصغرة (micro-batch) إذا كانت ستؤدي إلى تأخير.
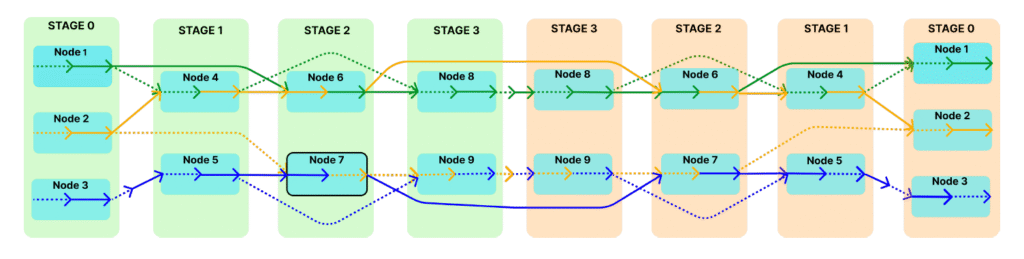
يستخدم SkipPipe خوارزمية جدولة جديدة لتحليل المسارات الحسابية المتاحة عبر الشبكة واختيار المسار الأمثل. هذا يقلل وقت خمول GPU ويزيد من القدرة على تحمل الأعطال، مما يتيح للنظام تجاوز العقد البطيئة أو غير العاملة.
الخاتمة
يوفر SkipPipe لبنة أساسية للتعلم الموزع (واللامركزي)، حيث يجمع بين الكفاءة الاتصالية والقدرة على تحمل الأعطال لخطوط الأنابيب، بينما ركزت الأعمال السابقة حصريًا على توازي البيانات. بالتركيز على توازي خطوط الأنابيب، نتخلص من قيد حجم النموذج الملازم للأساليب الحالية، مما يتيح للنماذج الفردية التوسع عبر عدة عقد موزعة بدلًا من مجرد تكرارها وتدريبها بالتوازي.
عند دمجه مع نظام التنسيق وأسلوب التحقق الموثوق، يسمح SkipPipe بتدريب فعّال لنماذج ضخمة متقدمة باستخدام الحوسبة الجماعية (crowdsourced computing).
لمعرفة المزيد، يمكنك قراءة المقال الكامل هنا.
SkipPipe مفتوح المصدر بالكامل، وندعو المجتمع البحثي للبناء على هذا الكود.