CheckFree: обучение с устойчивостью к сбоям без контрольных точек

Введение
CheckFree — это академическая работа, описывающая новый метод восстановления после сбоев в распределённом обучении, который не требует использования контрольных точек или избыточных вычислений, обеспечивая эффективное обучение при частых сбоях.
Основные моменты
- Ускорение до 1,6 раза по сравнению с традиционными контрольными точками: CheckFree и CheckFree+ могут достичь ускорения времени обучения до 1,6 раза по сравнению с традиционными контрольными точками при частых сбоях на этапах обучения.
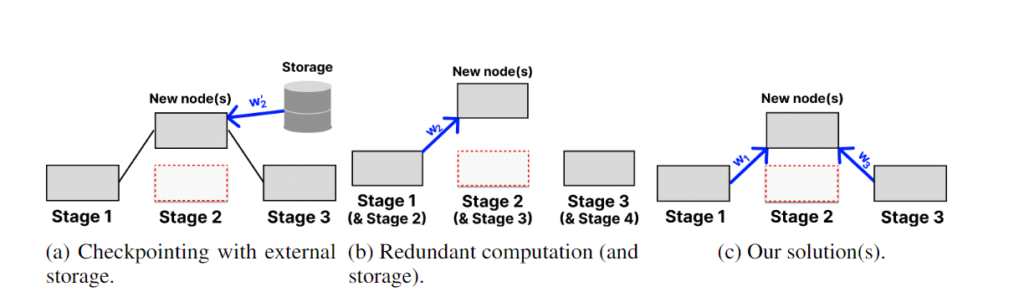
- Новая методика восстановления без контрольных точек: CheckFree использует веса соседних этапов для аппроксимации весов утраченного этапа.
Предпосылки
В современных стратегиях восстановления веса модели сохраняются (чекпоинтируются) периодически на надёжное централизованное хранилище. Это может быть чрезвычайно затратным, например, создание одной контрольной точки для модели LLaMa 70B занимает более 20 минут при высокоскоростном соединении (предполагая скорость более 500 Мбит/с). Когда происходит сбой, модель откатывается полностью к предыдущей контрольной точке, теряя потенциально часы обучения.
Bamboo предложил альтернативу чекпоинтингу — избыточные вычисления, сохраняя веса этапа на предыдущем этапе и выполняя каждый микропакет вперёд на копиях. Таким образом, при сбое обучение может быть немедленно возобновлено. Однако такое обучение оказывается неэффективным для крупных моделей, так как каждый узел должен удвоить свои требования к памяти для хранения избыточных слоёв.
CheckFree и CheckFree+ предоставляют жизнеспособную альтернативу в крупномасштабном геораспределённом обучении, так как не требуют дополнительных вычислений или коммуникаций.
Как это работает
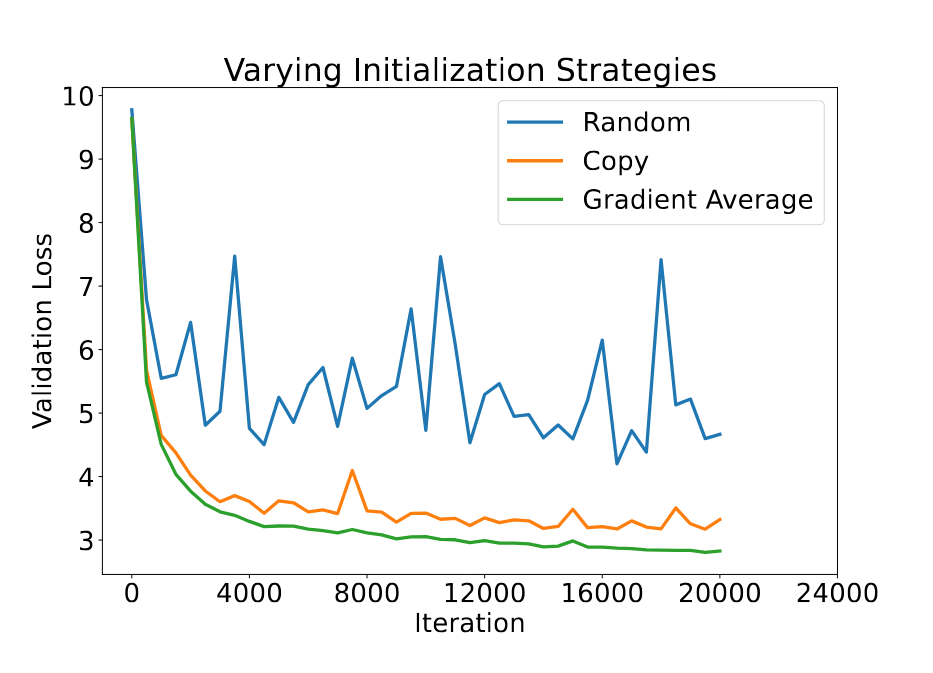
Когда происходит сбой, утраченный этап восстанавливается путём взвешенного среднего его двух соседей. Это использует естественную избыточность слоёв в LLM, как показано в предыдущих работах, где удаление нескольких слоёв не оказывает значительного воздействия на производительность модели. Мы эмпирически демонстрируем, что усреднение значительно превосходит простое копирование, обычно используемое в работах по стекованию слоёв.
Простой способ усреднения — это равномерное усреднение двух этапов. Такое усреднение, однако, не различает важность и сходимость этапов, что приводит к более медленной сходимости всей модели. Поэтому CheckFree использует веса последней нормы градиента данного этапа. Концептуально это даёт больший вес этапам, которые ещё не сошлись, частично разгружая их функциональность на новый этап. Чтобы позволить вновь инициализированному этапу «наверстать упущенное», CheckFree немного увеличивает скорость обучения на несколько шагов после восстановления.
Однако эта стратегия не может восстановить веса первого и последнего этапов, так как нет соседних этапов для усреднения. Для этого мы предлагаем CheckFree+. Он позволяет восстанавливать крайние этапы, используя выполнение вне очереди: каждый второй пакет меняет порядок первых двух и последних двух этапов, позволяя промежуточным слоям изучать поведение своих соседей, подобно избыточным вычислениям, но без дополнительных накладных расходов на память или вычисления. В случае сбоя «избыточные» этапы могут быть скопированы для замены отсутствующих.
Результаты
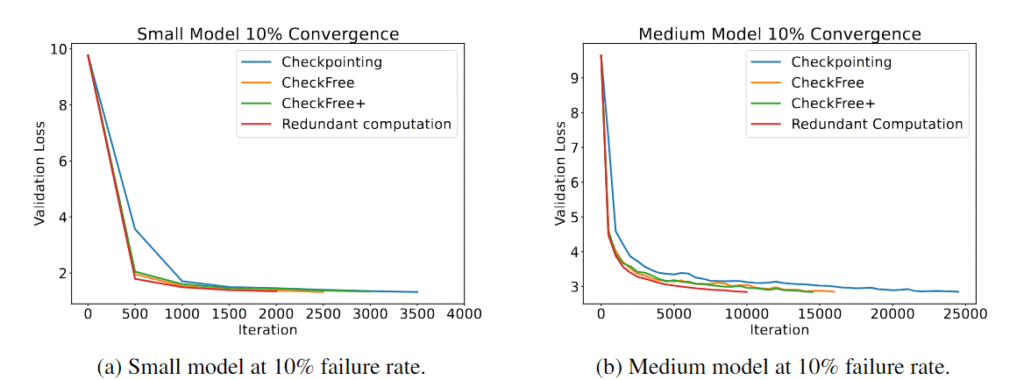
Мы широко оцениваем CheckFree и CheckFree+ при частоте сбоев от 5% до 16% в час по сравнению с традиционными контрольными точками и избыточными вычислениями. Мы наблюдаем, что на различных размерах моделей CheckFree и CheckFree+ могут сходиться быстрее по времени реального обучения по сравнению с современными методами. Однако наши методы приводят к снижению сходимости по итерациям относительно базовой линии без сбоев (сходимость, эквивалентная избыточным вычислениям). Но благодаря своей лёгкой процедуре восстановления CheckFree и CheckFree+ могут иметь гораздо более высокую пропускную способность, что делает их хорошо подходящими для геораспределённого обучения крупных языковых моделей.
Почему это важно
В децентрализованном обучении узлы могут входить и выходить из сети в любой момент, что может привести к сбою целого этапа. Даже при распределённом обучении на преемственных экземплярах возможно потерять целый этап, если соответствующие узлы запланированы в одном регионе. Контрольные точки могут нести большие накладные расходы из-за частых перезапусков, в то время как избыточные вычисления могут быть невозможны для крупных моделей из-за линейного увеличения памяти. CheckFree предлагает эффективный способ восстановления обучения LLM без дополнительных вычислений или коммуникаций.
Узнать больше
- Прочитать статью
- Изучить репозиторий
- Присоединиться к обсуждению: Discord · X
Дополнительные материалы
- Introducing BlockAssist: BlockAssist — это ИИ-помощник Minecraft, который учится на действиях пользователей в игре.
- Introducing RL Swarm’s new backend: GenRL: GenRL — это новая система, предназначенная для упрощения и ускорения создания сложных RL-сред, особенно тех, которые включают несколько агентов.
- NoLoCo: training large models with no all-reduce: NoLoCo — это метод оптимизации для распределённого обучения, который заменяет глобальную синхронизацию на метод обмена сообщениями, позволяя обучение в гетерогенных и низкоскоростных сетях.