Diverse Expert Ensembles:基于不同专家的并行 LLM

这篇论文讨论了在并行处理专家集成时,异质性(不同模型大小和训练步数)的优势。我们发现,使用不同计算资源、在不同时间训练的多样化模型,在集合时表现出比同质模型(使用相同配置训练的模型)更好的性能。
Diverse Expert Ensembles
混合专家(Mixture-of-Experts,MoE)模型因其计算效率和性能而日益流行。然而,尽管其具有模块化结构,我们仍然以与密集型单体网络相同的方式训练它们。也就是说,在由单一组织管理的大型数据中心中,使用相同的计算资源和专家的超参数来训练模型。
在 Gensyn,我们早已坚信,通用人工智能(AGI)将是一个开放的相互关联的模型生态系统——类似于互联网本身——而不是由单一公司提供的单体模型。此外,模型的多样性将强化这一生态系统,而不是削弱它。
今天,我们很高兴展示我们在支持这一假设方面的初步成果。
Introducing Heterogeneous Domain Expert Ensemble (HDEE)
HDEE 是一个创建多样化专家集成(即异质 MoE 模型)的框架,采用并行训练方法。
HDEE 基于 并行训练 方法 Branch Train Merge(BTM),该方法来自 Li 等人2022年的研究,显示“可以独立地在不同的数据子集上训练新的 LLM 子模型,避免目前为训练 LLM 所必需的大规模多任务同步”。我们的工作表明,将 BTM 扩展以使用异质的模型大小和训练参数(即支持不同的计算能力)实际上 提高了随后的集成模型的性能。
具体来说,HDEE 并不是使用相同的设置训练所有专家,而是根据每个专家的数据领域和/或计算能力来选择每个专家。对于较简单的领域,使用较小的模型(或使用较少迭代训练的模型);对于更复杂的领域,使用更大的模型并进行更长时间的训练。
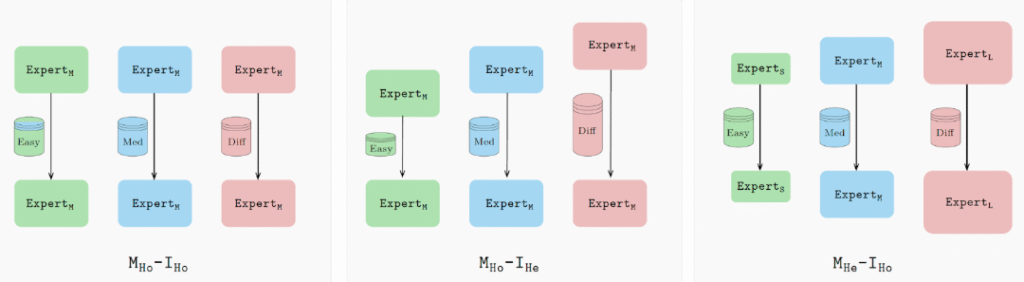
这些配置确保每个专家都得到优化,从而带来更强大的集成。总体而言,异质集合在与基础模型相比的 21 个领域中,达到最佳困惑度(perplexity),并且使用相同的计算预算。
展望未来
HDEE 提供了对开放模型生态系统的初步看法。独立开发者可以在各种硬件上训练模型,使用适合其数据和专业领域的配置。HDEE 和类似的方法可以将它们集成成元模型,指引请求通过最佳路径,类似于互联网的工作方式。
Gensyn 正在为此开发核心基础设施,使开发者能够在全球所有支持 ML 的设备上训练、验证和集成自己的模型。
要了解更多信息,您可以在这里阅读完整的文章。
HDEE 完全开放,我们鼓励研究社区基于此代码构建他们的开发。