Diverse Expert Ensembles: Збірки різноманітних експертів: паралельні LLM на основі різних спеціалістів

Це наукова робота, в якій розглядаються переваги гетерогенності (різні розміри моделей і кількість кроків навчання) при навчанні ансамблів експертів з паралельною обробкою. Ми виявили, що різноманітні моделі, навчені на різних обчислювальних джерелах протягом різного часу, показують кращу продуктивність при об’єднанні, ніж однорідні моделі, навчені з однаковими налаштуваннями.
Diverse Expert Ensembles
Моделі типу Mixture-of-Experts (MoE) продовжують набирати популярність завдяки своїй обчислювальній ефективності та продуктивності. Однак, незважаючи на свою модульну структуру, ми все одно навчаємо їх так само, як і щільні монолітні мережі. Тобто, в великих дата-центрах, керованих однією організацією, з використанням однорідних обчислювальних ресурсів і гіперпараметрів експертів.
У Gensyn ми давно дотримуємося думки, що AGI буде представляти собою відкриту екосистему взаємопов’язаних моделей — подібно самому інтернету — а не монолітну модель від однієї компанії. Більше того, різноманітність моделей буде посилювати цю екосистему, а не ослаблювати її.
Сьогодні ми раді представити наші перші результати на підтримку цієї гіпотези.
Введення в Heterogeneous Domain Expert Ensemble (HDEE)
HDEE — це фреймворк для створення різноманітних збірок експертів, тобто гетерогенних моделей MoE, що навчаються за допомогою паралельного навчання.
HDEE базується на методі паралельного навчання Branch Train Merge (BTM) з роботи Li et al., 2022, де показано, що «можливо незалежно навчати підмоделі нового класу LLM на різних підмножинах даних, виключаючи масову багатозадачну синхронізацію, яка зараз потрібна для навчання LLM». Наша робота демонструє, що розширення BTM для використання гетерогенних розмірів моделей і параметрів навчання (тобто підтримка різних обчислювальних можливостей) фактично збільшує продуктивність подальшої об’єднаної моделі.
Конкретно, замість того щоб навчати всіх експертів з однаковими налаштуваннями, HDEE підбирає кожен експерт залежно від його домену даних і/або обчислювальних можливостей. Для простіших доменів використовується менша модель (або модель, навчена з меншою кількістю ітерацій); для більш складних доменів застосовуються більш великі моделі та більш тривале навчання.
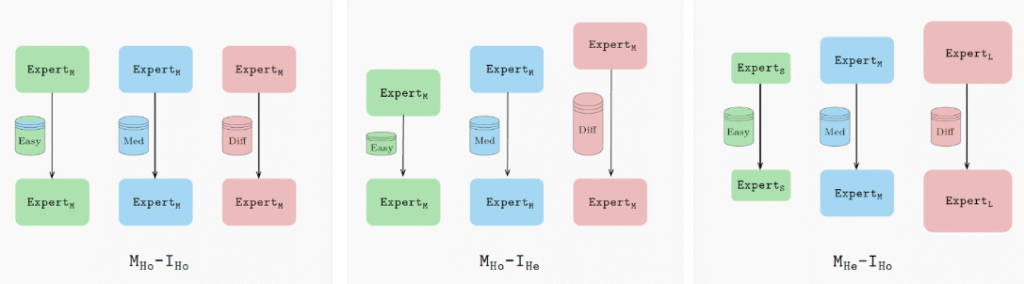
Ці конфігурації гарантують, що кожен експерт буде оптимально налаштований, що призводить до більш здатної збірки. В цілому, гетерогенна збірка досягає найкращої перплексії в 20 з 21 оцінених доменів порівняно з базовою моделлю, використовуючи еквівалентний обчислювальний бюджет.
Погляд у майбутнє
HDEE надає ранній погляд на відкриту екосистему моделей. Незалежні розробники можуть навчати моделі на різноманітному обладнанні, використовуючи конфігурації, що підходять для їхніх даних і областей експертизи. HDEE і подібні методи можуть об’єднувати їх в мета-моделі, які направляють запити по найкращому шляху, багато в чому нагадуючи сам інтернет.
Gensyn розробляє основну інфраструктуру для цього, дозволяючи розробникам навчати, перевіряти і об’єднувати свої моделі на всьому ML-спроможному обладнанні світу.
Щоб дізнатися більше, ви можете прочитати повну статтю тут.
HDEE повністю відкритий, і ми закликаємо дослідницьку спільноту будувати свої розробки на основі цього коду.