Diverse Expert Ensembles: विभिन्न विशेषज्ञों पर आधारित समानांतर LLM

यह एक वैज्ञानिक लेख है, जिसमें समानांतर प्रोसेसिंग के साथ विशेषज्ञों के समूह को प्रशिक्षित करने में गेटेरोजेनेटी के फायदे (विभिन्न मॉडल के आकार और प्रशिक्षण कदमों की संख्या) पर चर्चा की गई है। हमने पाया कि विभिन्न मॉडल, जो विभिन्न कंप्यूटिंग स्रोतों पर अलग-अलग समय में प्रशिक्षित किए जाते हैं, उनके संयोजन पर बेहतर प्रदर्शन दिखाते हैं, बजाय उन समान मॉडल के, जो समान सेटिंग्स के साथ प्रशिक्षित होते हैं।
Diverse Expert Ensembles
Mixture-of-Experts (MoE) प्रकार के मॉडल अपनी गणना क्षमता और प्रदर्शन के कारण लोकप्रियता प्राप्त कर रहे हैं। हालांकि, अपनी मॉड्यूलर संरचना के बावजूद, हम अभी भी इन्हें वैसे ही प्रशिक्षित करते हैं जैसे घने मोनोलीथिक नेटवर्क्स को। यानी, एक ही संगठन द्वारा प्रबंधित बड़े डेटा सेंटर में, समान कंप्यूटिंग संसाधनों और विशेषज्ञों के हाइपरपैरामीटर का उपयोग करते हुए।
Gensyn में, हम लंबे समय से इस विचार को मानते हैं कि AGI एक खुली पारिस्थितिकी तंत्र होगा, जो आपस में जुड़े मॉडल्स पर आधारित होगा — इंटरनेट की तरह — और न कि एक कंपनी से एक ही मोनोलीथिक मॉडल। इसके अलावा, मॉडल्स की विविधता इस पारिस्थितिकी तंत्र को कमजोर नहीं, बल्कि इसे मजबूत करेगी।
आज हम इस सिद्धांत का समर्थन करने के लिए अपने पहले परिणाम पेश करने के लिए खुश हैं।
Introducing Heterogeneous Domain Expert Ensemble (HDEE)
HDEE एक फ्रेमवर्क है जो विविध विशेषज्ञों के निर्माण के लिए है, यानी MoE के गेटेरोजेनेस मॉडल, जो समानांतर शिक्षा के उपयोग से प्रशिक्षित होते हैं।
HDEE पैरेलल लर्निंग Branch Train Merge (BTM) पद्धति पर आधारित है, जो Li et al. 2022 के काम से लिया गया है, जिसमें दिखाया गया है कि “नए प्रकार के LLM के उप-मॉडल्स को विभिन्न डेटा सबसेट्स पर स्वतंत्र रूप से प्रशिक्षित किया जा सकता है, जिससे वर्तमान में LLM के प्रशिक्षण के लिए आवश्यक बड़े पैमाने पर मल्टीटास्क सिंक्रनाइज़ेशन की आवश्यकता समाप्त हो जाती है।” हमारा काम यह दिखाता है कि BTM का विस्तार गेटेरोजेनेस मॉडल आकारों और प्रशिक्षण पैरामीटरों के लिए (यानी विभिन्न कंप्यूटिंग क्षमताओं का समर्थन) वास्तव में संयोजित मॉडल के प्रदर्शन को बढ़ाता है।
विशेष रूप से, सभी विशेषज्ञों को समान सेटिंग्स के साथ प्रशिक्षित करने के बजाय, HDEE प्रत्येक विशेषज्ञ का चयन उनके डेटा डोमेन और/या कंप्यूटिंग क्षमताओं के आधार पर करता है। सरल डोमेन के लिए छोटा मॉडल (या एक मॉडल, जो कम इटरशन के साथ प्रशिक्षित है) इस्तेमाल किया जाता है; जटिल डोमेन के लिए बड़े मॉडल और अधिक लंबा प्रशिक्षण लागू किया जाता है।
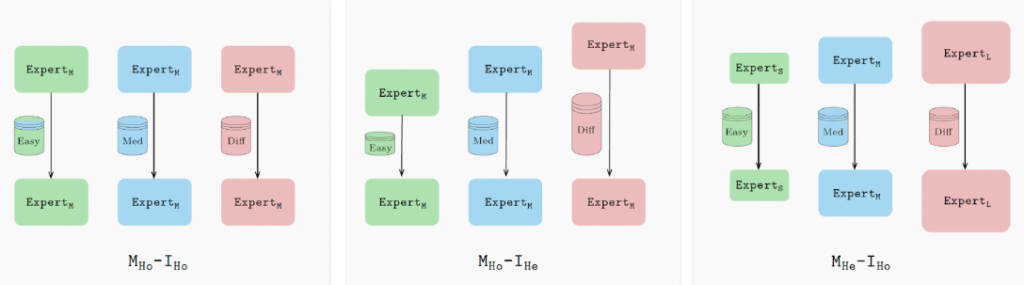
इन कॉन्फ़िगरेशन से यह सुनिश्चित होता है कि प्रत्येक विशेषज्ञ का अनुकूलन किया गया हो, जो एक अधिक सक्षम निर्माण के लिए नेतृत्व करता है। कुल मिलाकर, गेटेरोजेनेस निर्माण बुनियादी मॉडल की तुलना में 21 में से 20 डोमेन पर सर्वोत्तम पर्प्लेक्सिटी प्राप्त करता है, समान कंप्यूटिंग बजट का उपयोग करते हुए।
भविष्य की ओर एक दृष्टि
HDEE मॉडल्स के लिए एक खुले पारिस्थितिकी तंत्र की प्रारंभिक झलक प्रदान करता है। स्वतंत्र डेवलपर्स विभिन्न उपकरणों पर अपने मॉडल्स को प्रशिक्षित कर सकते हैं, जो उनके डेटा और विशेषज्ञता के क्षेत्रों के लिए उपयुक्त कॉन्फ़िगरेशन का उपयोग करते हैं। HDEE और इस तरह के तरीके उन्हें मेटा-मॉडल्स में एकत्र कर सकते हैं, जो अनुरोधों को सबसे उपयुक्त मार्ग पर मार्गदर्शित करते हैं, जो इंटरनेट जैसा दिखता है।
Gensyn इस प्रक्रिया के लिए मुख्य इन्फ्रास्ट्रक्चर पर काम कर रहा है, जो डेवलपर्स को प्रशिक्षण, सत्यापन, और दुनिया भर के सभी ML सक्षम उपकरणों पर अपने मॉडल्स को जोड़ने की अनुमति देता है।
अधिक जानने के लिए, आप पूर्ण लेख पढ़ सकते हैं यहां।
HDEE पूरी तरह से खुला है, और हम अनुसंधान समुदाय से इस कोड पर आधारित अपने विकास बनाने के लिए प्रोत्साहित करते हैं।