NoLoCo: बड़े मॉडलों को बिना all-reduce के प्रशिक्षण

यह एक वैज्ञानिक लेख है, जो NoLoCo का वर्णन करता है, एक नया वितरणित लर्निंग अनुकूलन तरीका, जो वैश्विक सिंक्रनाइज़ेशन चरण को गॉसिप विधि से बदलता है, जिससे कम बैंडविड्थ वाले हेटेरोजेनस नेटवर्क्स में लर्निंग को संभव बनाता है।
वर्तमान में बड़े मॉडलों को प्रशिक्षण देने की विधियां नोड्स के बीच बार-बार ग्रेडिएंट्स का आदान-प्रदान करने की आवश्यकता होती हैं, जो उच्च गति और कम विलंबता वाले कनेक्शनों की मांग करती हैं। अन्यथा, नोड्स अपडेट्स का इंतजार करते हुए निष्क्रिय रहते हैं। पहले प्रस्तावित विधियाँ, जैसे कि DiLoCo, संचार की लागत को घटाती हैं, all-reduce की आवृत्ति को घटाते हुए, लेकिन प्रत्येक घटना में फिर भी प्रत्येक प्रतिकृति शामिल होती है और इसलिए वही विलंबता सीमाएं बनी रहती हैं।
आज हम इस शोध दिशा को NoLoCo के साथ विस्तारित कर रहे हैं — एक ऐसा तरीका, जो पूरी तरह से वैश्विक all-reduce कदम को हटा देता है। SGD के एक छोटे से स्थानीय अपडेट ब्लॉक के बाद, प्रतिकृतियाँ एक यादृच्छिक प्रतिकृति के साथ वजन औसत करती हैं, जबकि सक्रियताएँ पाइपलाइन चरणों के बीच यादृच्छिक रूप से पुनःनिर्देशित की जाती हैं। इसमें एक संशोधित नेस्टेरोव कदम का उपयोग किया जाता है, जो पैरामीटर की संगति बनाए रखने के लिए काम करता है। इंटरनेट के माध्यम से कनेक्टेड 1000 GPU का उपयोग करते हुए किए गए प्रयोगों में, NoLoCo मानक डेटा параललिज़्म के समान वेलिडेशन परसिशन प्रदान करता है, जबकि सिंक्रनाइजेशन विलंबता को लगभग 10 गुना घटा देता है।
प्रमुख बिंदु
- कोई all-reduce नहीं
NoLoCo डेटा-पारललिज़्म को लागू करता है, लेकिन वैश्विक सिंक्रनाइज़ेशन (all-reduce) को हटा देता है, केवल छोटे जोड़े नोड्स के बीच डेटा का आदान-प्रदान करता है। - संचयन गति में कोई हानि नहीं
सक्रियताओं को पाइपलाइन चरणों के बीच यादृच्छिक मार्गनिर्देशन और नेस्टेरोव मोमेंटम में विशेष जोड़ने के कारण प्रतिकृतियों के बीच भिन्नता कम हो जाती है, जो वजन की विसंगति को नियंत्रित करता है। - मापदंडों पर 10× तेज़ सिंक्रनाइज़ेशन
1000 प्रतिकृतियों के साथ NoLoCo बेसलाइन की सटीकता बनाए रखते हुए प्रत्येक सिंक्रनाइज़ेशन कदम को tree all-reduce के मुकाबले तेज़ करता है।
बुनियादी बातें
मानक डेटा-समानांतर प्रशिक्षण (standard data-parallel training) में, प्रत्येक वर्कर अपने स्वयं के मिनी-बैच पर ग्रेडिएंट्स की गणना करता है और फिर एक क्लस्टर-व्यापी ऑल-रिड्यूस (all-reduce) में भाग लेता है ताकि प्रत्येक प्रतिकृति (replica) एक ही अपडेट देख सके। सामूहिक संचार (collective communication) प्रतिकृति की संख्या के साथ रैखिक रूप से बढ़ता है और सबसे धीमी लिंक (slowest link) द्वारा सीमित होता है। इंटरनेट से जुड़े नोड्स पर, यह चरण वॉल टाइम (wall time) पर हावी होता है और कम्प्यूट संसाधनों की बर्बादी करता है। डीलोको (DiLoCo) जैसी कम-संचार योजनाएं ऑल-रिड्यूस की आवृत्ति को कम करती हैं, लेकिन प्रत्येक सिंक्रनाइज़ेशन में अभी भी हर वर्कर शामिल होता है और इसलिए यह समान विलंब सीमा (latency bound) को विरासत में लेता है।
नोलोको (NoLoCo) दर्शाता है कि हम अभिसरण (convergence) को प्रभावित किए बिना इस ऑल-रिड्यूस सिंक्रनाइज़ेशन चरण से बच सकते हैं।
यह कैसे काम करता है
all-reduce ऑपरेशन को निष्पादित करने के बजाय, NoLoCo केवल छोटे, यादृच्छिक रूप से चुने गए प्रतिकृतियों को सिंक्रनाइज़ करता है (कम से कम दो)। इससे सिंक्रनाइज़ेशन समय की जटिलता ~log(N) पर घट जाती है, जहाँ N — मॉडल की प्रतिकृतियों की संख्या है। NoLoCo इस बात को सुनिश्चित करने के लिए अतिरिक्त उपाय करता है कि संकेंद्रण धीमा न हो। SWARM Parallelism और DiPaCo से प्रेरित होकर, NoLoCo पाइपलाइन चरणों के विभिन्न प्रतिकृतियों के बीच प्रशिक्षण डेटा को यादृच्छिक रूप से मार्गनिर्देशित करता है।
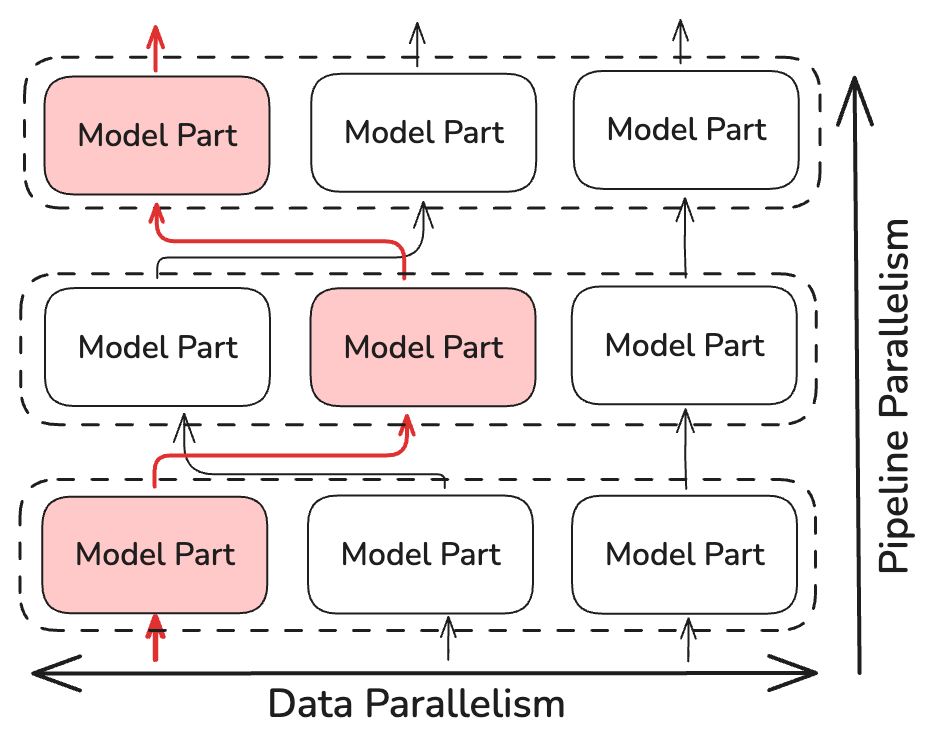
यह ग्रेडिएंट्स को पर्याप्त रूप से मिश्रित करने को सुनिश्चित करता है, जो कि समानांतर रूप से वितरित डेटा से आते हैं।
NoLoCo एक नया नेस्टेरोव मोमेंटम संस्करण भी उपयोग करता है, जिसमें वजन को एक दूसरे के पास लाने के लिए एक तीसरा तत्व जोड़ा जाता है। अतिरिक्त तत्व को ध्यान में रखते हुए, नेस्टेरोव मोमेंटम का पूर्ण रूपांतरण इस प्रकार है:
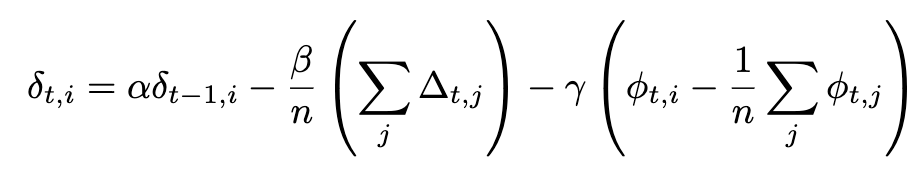
यदि सिंक्रनाइज़ेशन सभी कार्य नोड्स पर लागू किया जाता है, तो अंतिम तत्व समाप्त हो जाता है, और हम DiLoCo में उपयोग किए गए नेस्टेरोव मोमेंटम का मूल रूप पुनः प्राप्त कर लेते हैं। अतिरिक्त तत्वों को नीचे चित्रित किया गया है:
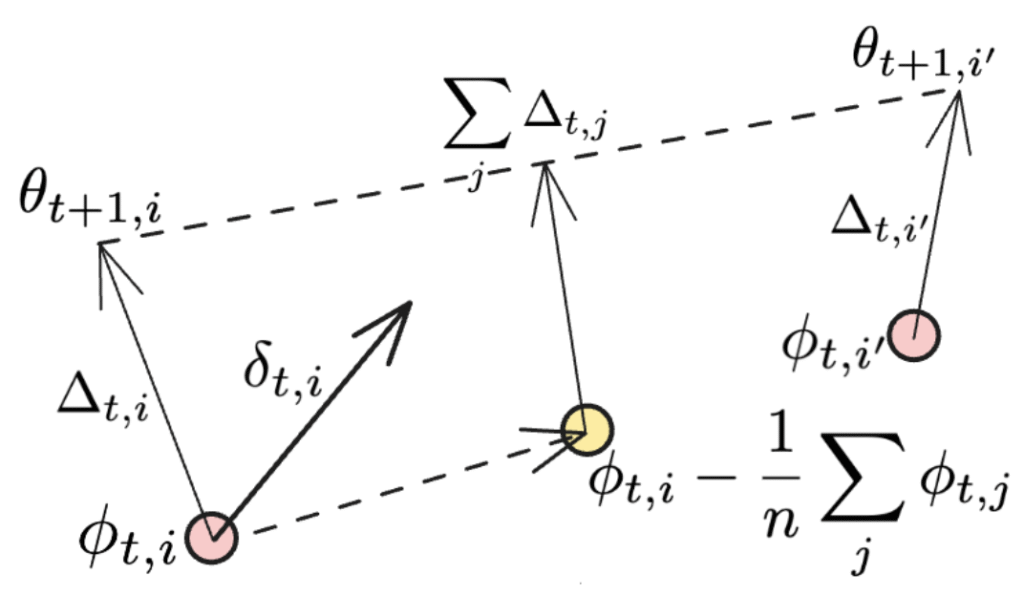
दूसरा तत्व दिशा का औसतकरण है, जहाँ प्रत्येक व्यक्तिगत NoLoCo कार्यकर्ता वजन को अपडेट करता है, जबकि अंतिम तत्व को एक और अपडेट के रूप में देखा जा सकता है, जो विभिन्न कार्यकर्ताओं के वजन को उनकी मूल स्थिति के करीब लाता है। जब यह कई पुनरावृत्तियों के दौरान किया जाता है, तो तीसरा तत्व “घुमाव” की तरह कार्य करेगा, जो वजन के औसत चयनित नमूनों को प्रशिक्षण के दौरान मिश्रित करता है।
सीधे शब्दों में, NoLoCo में निम्नलिखित कदम होते हैं:
- स्थानीय चरण। प्रत्येक प्रतिकृति SGD (स्टोकास्टिक ग्रेडिएंट डिसेंट) विधि से k अपडेट करता है।
- जोड़ी का औसतकरण। फिर यह यादृच्छिक रूप से एक साथी का चयन करता है और नेस्टेरोव नियम का उपयोग करके वजन का औसत करता है, जो ड्रिफ्ट को सीमित करता है।
- यादृच्छिक मार्गनिर्देशन। स्थानीय चरण के दौरान सक्रियताएँ यादृच्छिक साझेदारों के बीच भेजी जाती हैं, जो ग्रेडिएंट्स के निरंतर मिश्रण को सुनिश्चित करती हैं।
परिणाम
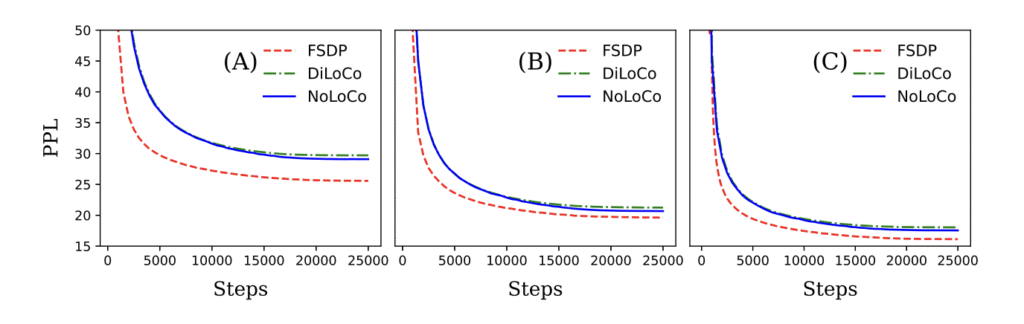
हमने सिद्धांत और अनुभव दोनों के आधार पर यह प्रदर्शित किया कि NoLoCo संकेंद्रण बनाए रखते हुए संचार आवश्यकताओं को महत्वपूर्ण रूप से घटाता है। इन विधियों का उपयोग करके, NoLoCo लाखों से लेकर अरबों पैरामीटर वाले मॉडल को प्रभावी ढंग से प्रशिक्षित करता है। हमारे Llama-शैली के मॉडल के प्रयोग, जो 125 मिलियन से 6.8 बिलियन पैरामीटर तक भिन्न होते हैं, 1000 प्रतिकृतियों के साथ, दिखाते हैं कि NoLoCo के सिंक्रनाइज़ेशन कदम DiLoCo की तुलना में एक आदेश तेज होते हैं और साथ ही जल्दी संकेंद्रित होते हैं। इसके अलावा, सिंक्रनाइज़ेशन रणनीति और संशोधित ऑप्टिमाइज़र को अन्य प्रशिक्षण प्रोटोकॉल और मॉडल आर्किटेक्चर में सहजता से एकीकृत किया जा सकता है।
यह क्यों महत्वपूर्ण है
वैश्विक all-reduce ऑपरेशन को हटाने से बड़े मॉडल्स को प्रशिक्षित करने के लिए बुनियादी ढांचे की आवश्यकता कम हो जाती है, जिससे शोधकर्ताओं को विशेष कनेक्शन के बिना विकेन्द्रीकृत उपकरणों का बेहतर उपयोग करने का अवसर मिलता है। हम NoLoCo को खुले स्रोत के रूप में प्रस्तुत करने के लिए खुश हैं, जो खुले मशीन लर्निंग की सीमाओं को आगे बढ़ाने में मदद करेगा।
और अधिक जानें
लेख पढ़ें
रिपॉजिटरी का अध्ययन करें – बेंचमार्क, स्क्रिप्ट और 100 लाइन का न्यूनतम कार्यान्वयन।
हमारे Discord पर चर्चा में शामिल हों या X पर हमें फॉलो करें।