CheckFree: 실패에 대한 내성 있는 학습, 체크포인트 없이

CheckFree는 체크포인트나 중복 계산을 사용하지 않고 분산 학습에서의 실패 복구를 위한 새로운 방법을 설명하는 학술 논문입니다. 이 방법은 빈번한 실패가 발생하는 학습 단계에서도 효율적인 학습을 보장합니다.
주요 사항
- 전통적인 체크포인트와 비교하여 최대 1.6배 가속화: CheckFree와 CheckFree+는 학습 단계에서 자주 발생하는 실패 상황에서 체크포인트를 사용할 때보다 최대 1.6배 더 빠른 학습 시간을 달성할 수 있습니다.
- 체크포인트 없이 새로운 복구 방법: CheckFree는 잃어버린 단계를 근처 단계들의 가중치로 근사화합니다.
배경
최신 복구 전략에서는 모델 가중치를 비결함 중앙 집중식 저장소에 주기적으로 저장합니다(체크포인트). 이는 매우 비용이 많이 들 수 있는데, 높은 대역폭 연결(500Mb/s 이상 가정)에서 단일 LLaMa 70B 체크포인트에 20분 이상 소요됩니다. 결함이 발생하면 모델은 이전 체크포인트로 완전히 롤백되므로 수 시간의 훈련 결과를 잃을 수 있습니다. Bamboo는 체크포인트의 대안으로 중복 계산을 제안했습니다. 이는 이전 단계에 단계의 가중치를 저장하고 각 마이크로배치의 순전파를 복사본에서 중복 실행하는 방식입니다. 이렇게 하면 단일 결함이 발생해도 훈련을 즉시 재개할 수 있습니다. 그러나 이러한 훈련은 각 노드가 중복 레이어를 저장하기 위해 메모리 요구 사항을 두 배로 늘려야 하기 때문에 대형 모델에는 비효율적입니다. CheckFree와 CheckFree+는 추가 계산이나 통신이 필요하지 않아 대규모 지리적으로 분산된 훈련에 실용적인 대안을 제공합니다.
작동 방식
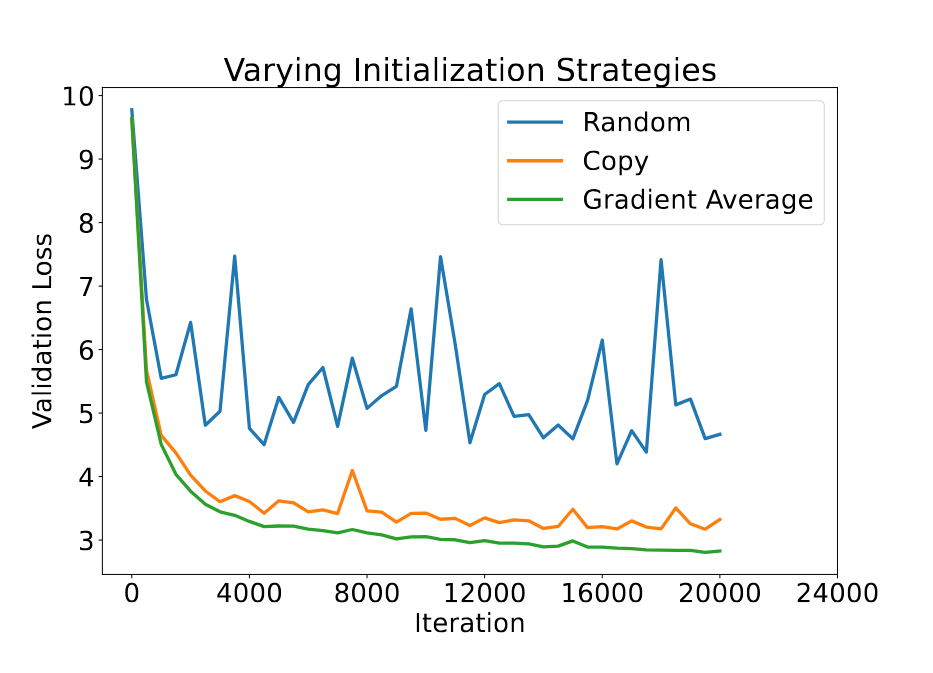
실패가 발생하면, 잃어버린 단계를 두 인접 단계의 가중치로 복구합니다. 이는 LLM에서 레이어의 자연스러운 중복성을 활용한 방법으로, 여러 레이어를 제거해도 모델 성능에 큰 영향을 미치지 않음을 이전 연구에서 보여주었습니다. 우리는 평균화가 레이어 스태킹에서 일반적으로 사용되는 단순한 복사보다 훨씬 효과적이라는 것을 경험적으로 증명합니다.
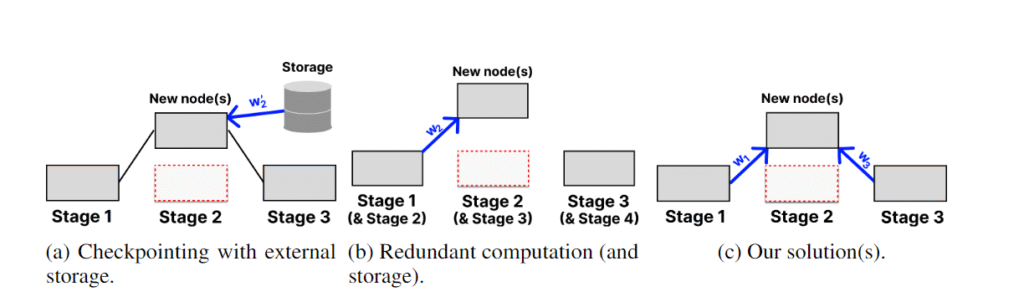
평균화의 간단한 방법은 두 단계의 가중치를 동일하게 평균내는 것입니다. 그러나 이런 방식은 각 단계의 중요도와 수렴 속도를 구별하지 않기 때문에 전체 모델의 수렴 속도를 느리게 만듭니다. 따라서 CheckFree는 각 단계의 마지막 그라디언트 규범을 사용하여 가중치를 평균화합니다. 이 방식은 아직 수렴하지 않은 단계에 더 많은 가중치를 부여하며, 새로운 단계가 “잃어버린 부분을 따라잡을” 수 있도록 학습 속도를 약간 높입니다.
하지만 이 전략은 첫 번째 및 마지막 단계의 가중치를 복구할 수 없습니다. 왜냐하면 이들 단계에는 인접한 단계가 없기 때문입니다. 이를 위해 우리는 CheckFree+를 제안합니다. CheckFree+는 비순차 실행을 사용하여 극단적인 단계를 복구할 수 있게 합니다. 각 두 번째 배치는 첫 번째 두 단계와 마지막 두 단계의 순서를 변경하여, 중간 레이어가 이웃 단계들의 행동을 학습할 수 있도록 합니다. 이는 중복 계산처럼 작동하지만 추가적인 메모리나 계산 비용이 발생하지 않습니다. 실패가 발생하면 “중복된” 단계들이 복사되어 누락된 부분을 채웁니다.
결과
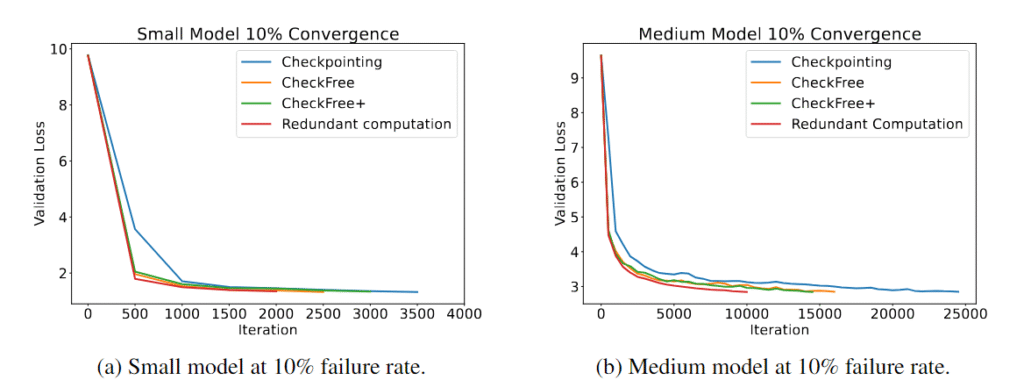
우리는 실패율이 시간당 5%에서 16% 사이일 때, CheckFree와 CheckFree+를 전통적인 체크포인트 및 중복 계산 방식과 비교하여 광범위하게 평가했습니다. 다양한 모델 크기에서 CheckFree와 CheckFree+가 현대적인 방법들과 비교하여 실제 학습 시간을 더 빨리 수렴할 수 있음을 확인했습니다. 하지만 우리의 방법들은 실패가 없는 기본 선형 모델에 비해 반복 횟수에서는 수렴도가 낮아졌습니다(중복 계산과 동등한 수렴도). 그럼에도 불구하고, CheckFree와 CheckFree+는 간단한 복구 절차 덕분에 훨씬 더 높은 처리량을 가질 수 있으며, 대형 언어 모델의 지리 분산 학습에 매우 적합합니다.
왜 중요한가
분산 학습에서는 노드가 언제든지 네트워크에 들어오거나 나갈 수 있기 때문에 전체 단계가 실패할 수 있습니다. 계승 인스턴스를 사용하는 분산 학습에서도 특정 지역에서 해당 노드들이 예약되어 있으면 전체 단계를 잃을 수 있습니다. 체크포인트는 자주 재시작해야 하므로 큰 오버헤드를 발생시키고, 대형 모델에서는 중복 계산이 메모리 요구사항이 선형적으로 증가하므로 불가능할 수 있습니다. CheckFree는 추가 계산이나 통신 없이 LLM 학습을 효율적으로 복구하는 방법을 제공합니다.