NoLoCo: all-reduce 없이 대형 모델 훈련

이 학술 논문은 글로벌 동기화 단계를 가십(gossip) 방식으로 대체하여 이질적인 환경과 낮은 대역폭 네트워크에서의 학습을 가능하게 하는 새로운 분산 학습 최적화 방법인 NoLoCo를 소개합니다.
대형 모델을 훈련하는 현재 방법들은 노드 간 자주 그라디언트를 교환해야 하며, 이는 고속 저지연 연결을 필요로 합니다. 그렇지 않으면 노드는 업데이트를 기다리며 비활성화됩니다. 이전에 제안된 방법들, 예를 들어 DiLoCo는 통신 비용을 낮추기 위해 all-reduce의 빈도를 줄였지만, 여전히 각 이벤트는 각 복제본을 포함하며, 따라서 여전히 지연 제한이 있습니다.
오늘, 우리는 NoLoCo를 소개합니다 — global all-reduce 단계를 완전히 제외한 방법입니다. NoLoCo는 짧은 로컬 SGD 업데이트 후, 각 복제본이 무작위로 선택된 다른 복제본과 가중치를 평균화하고, 활성화 함수는 파이프라인 단계 간에 무작위로 리디렉션됩니다. 이를 통해 파라미터 일관성을 유지하기 위해 수정된 Nesterov 모멘텀이 사용됩니다. 인터넷을 통해 최대 1000개의 GPU를 활용한 실험에서는, NoLoCo가 데이터 병렬 처리 방식과 동일한 검증 정확도를 제공하면서도 동기화 지연을 약 10배 줄였습니다.
주요 특징
- No all-reduce
NoLoCo는 데이터 병렬화를 적용하면서도 global synchronization (all-reduce)을 제외하고, 작은 쌍의 노드 간에만 데이터를 교환합니다. - 수렴 속도 손실 없음
파이프라인 단계 간 무작위 활성화 라우팅과, 가중치 확산을 제어하는 Nesterov 모멘텀을 추가하여 복제본 간 차이를 줄입니다. - 10배 빠른 동기화
1,000개의 복제본이 있을 경우, NoLoCo는 tree all-reduce 방식보다 동기화 단계를 가속화하며 baseline 정확도를 유지합니다.
기본 개념
표준 데이터 병렬 학습에서는 각 작업 노드가 자신의 미니 배치에서 그라디언트를 계산한 후, all-reduce 클러스터 작업에 참여하여 각 복제본이 동일한 업데이트를 받도록 합니다. 집합적인 통신은 복제본 수에 따라 선형적으로 확장되며, 가장 느린 연결 속도에 의해 제한됩니다. 인터넷을 통해 연결된 노드에서는 이 단계가 실행 시간에서 대부분을 차지하며, 계산 자원을 낭비합니다. DiLoCo와 같은 낮은 통신 오버헤드를 사용하는 방법들은 all-reduce 연산 빈도를 줄여서 이를 해결하지만, 여전히 모든 노드를 포함하는 동기화가 필요하기 때문에 지연이 여전히 발생합니다.
NoLoCo는 all-reduce 동기화를 피하면서도 수렴 속도를 저하시키지 않음을 보여줍니다.
작동 방식
all-reduce 연산을 수행하는 대신, NoLoCo는 무작위로 선택된 몇 개의 복제본(최소 두 개)만 동기화합니다. 이는 동기화 시간 복잡도를 ~log(N)로 줄여주며, 여기서 N은 모델 복제본 수입니다. NoLoCo는 수렴 속도가 느려지지 않도록 추가적인 조치를 취합니다. SWARM Parallelism 및 DiPaCo에서의 동적이고 무작위 라우팅 기법을 바탕으로, NoLoCo는 파이프라인 단계 간에 학습 데이터를 무작위로 라우팅합니다.
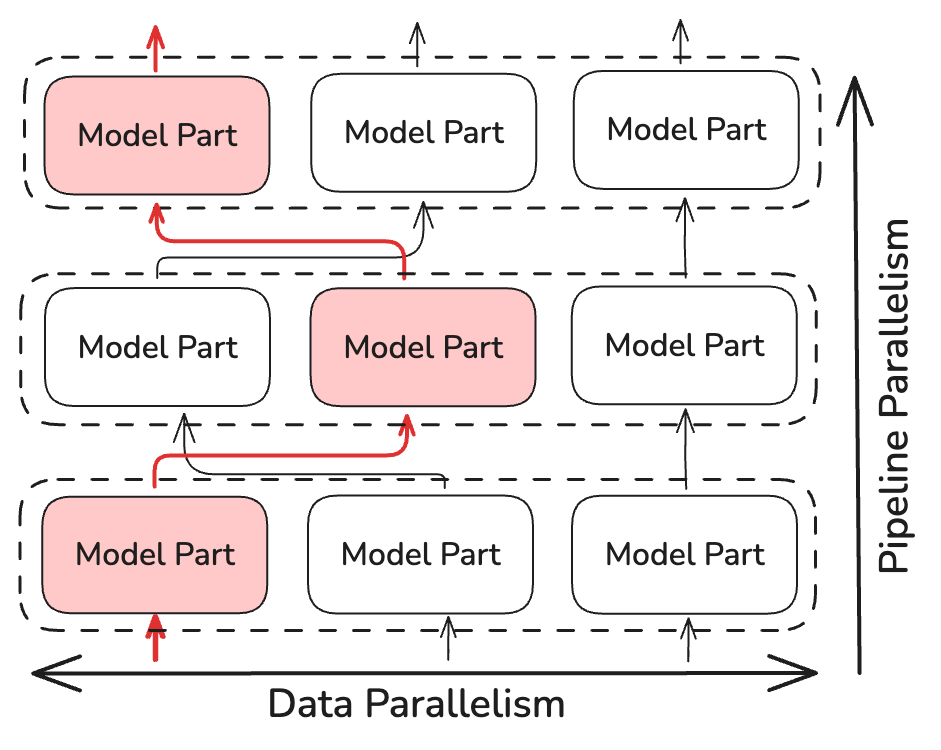
이는 병렬 인스턴스 간에 그라디언트를 충분히 섞는 역할을 합니다.
NoLoCo는 또한 새로운 형태의 Nesterov 모멘텀을 사용하며, 가중치를 서로 가까워지게 만드는 세 번째 항을 추가합니다. 이 추가 항을 고려하면, Nesterov 모멘텀의 전체 표현식은 다음과 같습니다:
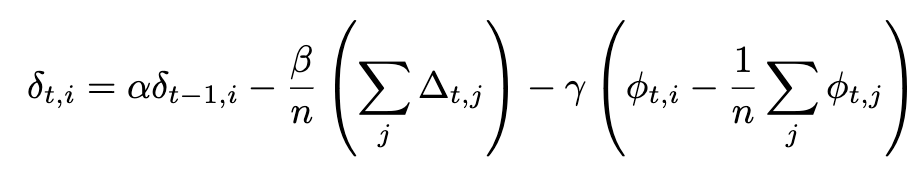
만약 동기화가 모든 작업 노드에 대해 적용된다면, 마지막 항은 사라지고, 우리는 DiLoCo에서 사용된 원래의 Nesterov 모멘텀 표현식을 복원합니다. 추가 항목은 아래 그림에서 설명됩니다:
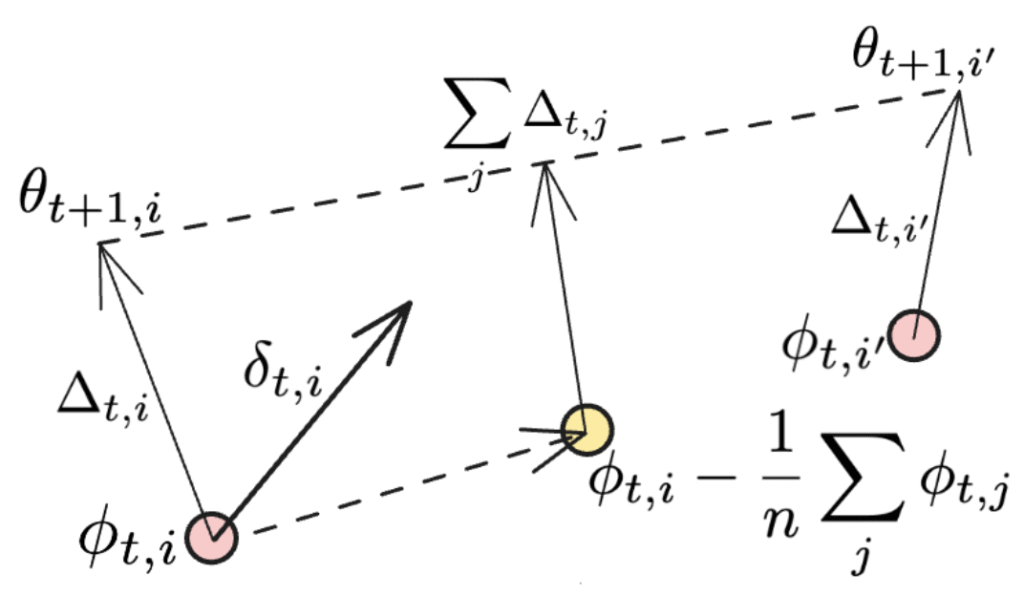
두 번째 항목은 방향의 평균을 나타내며, NoLoCo의 각 작업자는 가중치를 업데이트합니다. 마지막 항목은 또 다른 업데이트로, 서로 다른 작업자의 가중치를 원래의 위치로 더 가까워지게 합니다. 이 과정은 몇 번의 반복을 거치면서 세 번째 항이 복제본들의 평균된 가중치를 “구르는” 효과를 낳습니다.
간단히 말해, NoLoCo는 다음 단계를 포함합니다:
- 로컬 단계. 각 복제본은 SGD 방식으로 k번의 업데이트를 수행합니다.
- 쌍 평균화. 그런 다음, 무작위로 하나의 파트너를 선택하여 Nesterov 규칙을 사용해 가중치를 평균화하고, 이는 드리프트를 제한합니다.
- 무작위 라우팅. 로컬 단계 동안, 활성화는 무작위 파트너에게 전달되어 그라디언트가 지속적으로 섞입니다.
결과
우리는 NoLoCo가 이론적으로나 경험적으로 통신 요구 사항을 크게 줄이면서 수렴을 유지한다는 것을 입증했습니다. 이 방법을 사용하여 NoLoCo는 수백만에서 수십억 개의 파라미터로 된 모델을 효율적으로 훈련시킵니다. Llama 스타일 모델(125백만에서 68억 파라미터까지)을 사용하여 1000개 복제본에서 실험한 결과, NoLoCo의 동기화 단계가 DiLoCo보다 실제로 10배 빠르며, 더 빠르게 수렴함을 확인했습니다. 또한, 동기화 전략과 수정된 최적화 프로그램은 다른 학습 프로토콜과 모델 아키텍처에 원활하게 통합될 수 있습니다.

왜 중요한가
전역 all-reduce 연산을 없애면 대형 모델 훈련을 위한 인프라의 문턱을 낮출 수 있습니다. 이는 연구자들이 전문화된 연결 없이 분산된 장비를 더 잘 활용할 수 있게 해줍니다. 우리는 NoLoCo가 개방형 머신 러닝의 경계를 확장하는 완전 개방형 솔루션으로 자리잡기를 기대합니다.