NoLoCo: All-reduce Olmadan Büyük Modellerin Eğitilmesi

Bu bilimsel makale, NoLoCo’yu tanıtmaktadır. NoLoCo, düşük bant genişliğine sahip heterojen ağlarda eğitim yapmayı mümkün kılan ve küresel senkronizasyon aşamasını gossip yöntemiyle değiştiren yeni bir dağıtılmış öğrenme optimizasyon yöntemidir.
Modern büyük model eğitim yöntemleri, düğümler arasında sıklıkla gradient alışverişi gerektirir, bu da yüksek hızlı ve düşük gecikmeli bağlantılar gerektirir. Aksi takdirde, düğümler güncellemeleri beklerken pasif hale gelir. Daha önce önerilen yöntemler, örneğin DiLoCo, iletişim maliyetlerini azaltarak all-reduce sıklığını düşürür, ancak her olay yine de her kopyayı içerir ve bu nedenle gecikme sınırlamalarını miras alır.
Bugün, NoLoCo ile bu araştırma alanını genişletiyoruz — bu yöntem, küresel all-reduce adımını tamamen ortadan kaldırır. Kısa bir yerel SGD güncellemeleri bloğunun ardından, kopyalar, rastgele bir kopya ile ağırlıkları ortalama yapar, aynı zamanda aktivasyonlar, pipeline aşamaları arasında rastgele yönlendirilir. Parametre tutarlılığını sağlamak için modifiye edilmiş bir Nesterov adımı kullanılır. 1000 GPU ile yapılan internet bağlantılı deneylerde, NoLoCo, veri paralelliği ile aynı doğruluğu sağlar ve senkronizasyon gecikmesini yaklaşık 10 kat azaltır.
Ana Noktalar
- No all-reduce
NoLoCo, veri paralelliği uygular ancak küresel senkronizasyonu (all-reduce) ortadan kaldırır ve sadece küçük çiftler arasında veri paylaşır. - Hız kaybı olmadan yakınsama hızı
Kopyalar arasındaki sapma, pipeline aşamaları arasında rastgele yönlendirme ve ağırlık sapmalarını kontrol eden Nesterov momentumunun özel eklenmesiyle azaltılır. - Ölçeklenebilirlikte 10× daha hızlı senkronizasyon
1000 kopya ile NoLoCo, tree all-reduce’a kıyasla her senkronizasyon adımını hızlandırır ve baseline doğruluğunu korur.
Temel Bilgiler
Veri paralel işleme ile standart eğitimde, her iş düğümü kendi mini-batch’inde gradient hesaplaması yapar ve ardından her kopyanın aynı güncellemeyi alması için küme çapında all-reduce işlemi yapar. Kolektif iletişim, kopya sayısı ile doğrusal olarak ölçeklenir ve en yavaş bağlantı ile sınırlıdır. İnternet üzerinden bağlı düğümlerde, bu adım, işlem süresi bakımından baskın hale gelir ve hesaplama kaynaklarını tüketir. DiLoCo gibi düşük seviyeli iletişim şemaları, all-reduce işleminin sıklığını azaltır, ancak her senkronizasyon yine de her iş düğümünü içerir, bu da aynı gecikme sınırlamalarına yol açar.
NoLoCo, bu all-reduce senkronizasyonundan kaçınabileceğimizi ve yakınsamayı yavaşlatmadan sürdürebileceğimizi gösteriyor.
Nasıl Çalışır
All-reduce işlemi yerine, NoLoCo yalnızca küçük, rastgele seçilen kopyaları senkronize eder (en az iki kopya). Bu, senkronizasyon zamanının karmaşıklığını ~log(N) oranında azaltır, burada N modelin kopya sayısıdır. NoLoCo, yakınsamayı yavaşlatmamak için ek önlemler alır. SWARM Paralelizm ve DiPaCo gibi dinamik ve rastgele yönlendirme yöntemlerinden ilham alarak, NoLoCo, eğitim verilerini pipeline aşamalarındaki farklı kopyalar arasında rastgele yönlendirir.
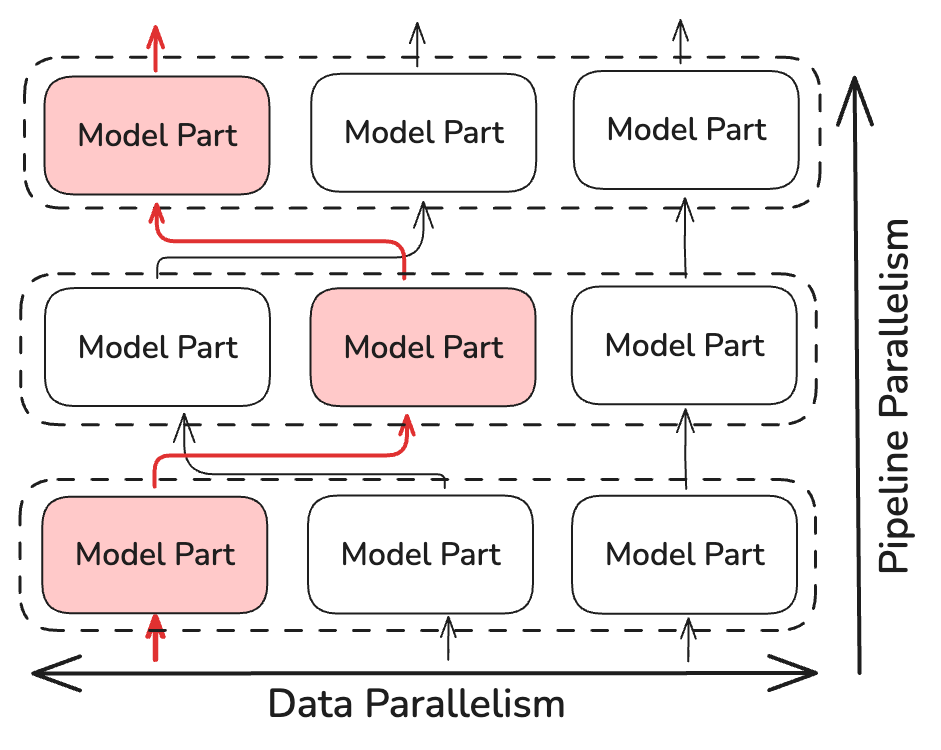
Bu, paralel örnekler arasında dağıtılmış verilerde yeterli derecede gradient karışımı sağlar.
NoLoCo ayrıca, kopyaların ağırlıklarını birbirine yaklaştıran üçüncü bir terimi ekleyerek, Nesterov momentumunun yeni bir versiyonunu kullanır. Ekstra terimi göz önünde bulundurarak, Nesterov momentumunun tam ifadesi şu hale gelir:
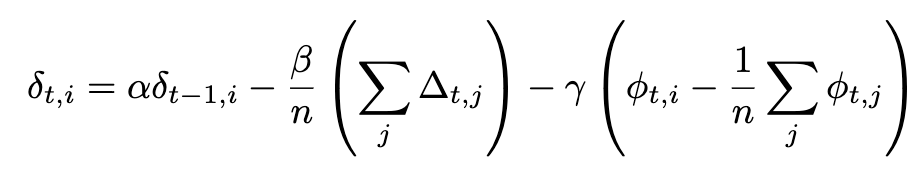
Eğer senkronizasyon tüm iş düğümlerine uygulanıyorsa, son terim kaybolur ve DiLoCo’da kullanılan orijinal Nesterov momentum ifadesi geri getirilir. Ekstra terimler aşağıdaki şekilde gösterilmektedir:
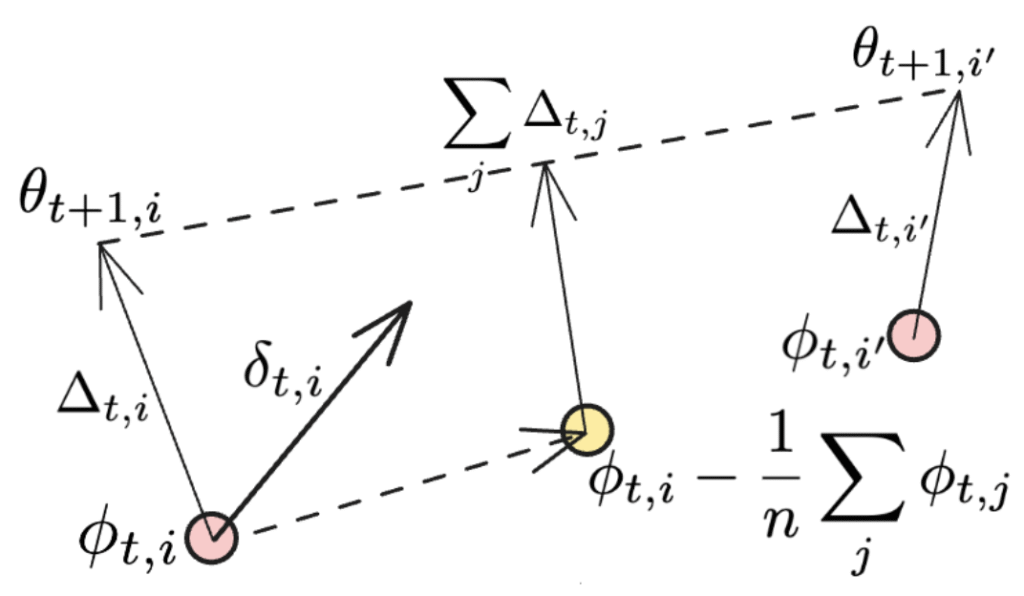
İkinci terim, her bireysel NoLoCo işçisinin ağırlıkları güncellediği yönün ortalamasıdır, son terim ise ağırlıkları birbirine yaklaştıran bir başka güncelleme olarak görülebilir. Bu, birkaç iterasyon boyunca yapıldığında, üçüncü terim, ağırlıkların ortalanmış örneklerini “yuvarlama” gibi benzer bir etki yaratır.
Basitçe söylemek gerekirse, NoLoCo şu adımları içerir:
- Yerel Aşama. Her kopya, stokastik gradyan inişi (SGD) yöntemiyle k güncellemesi yapar.
- Çiftler Arası Ortalama. Daha sonra rastgele bir partner seçer ve ağırlıkları Nesterov kuralı ile ortalar, bu da sapmayı sınırlar.
- Rastgele Yönlendirme. Yerel aşama sırasında, aktivasyonlar rastgele partnerlere yönlendirilerek gradientlerin sürekli karışımını sağlar.
Sonuçlar
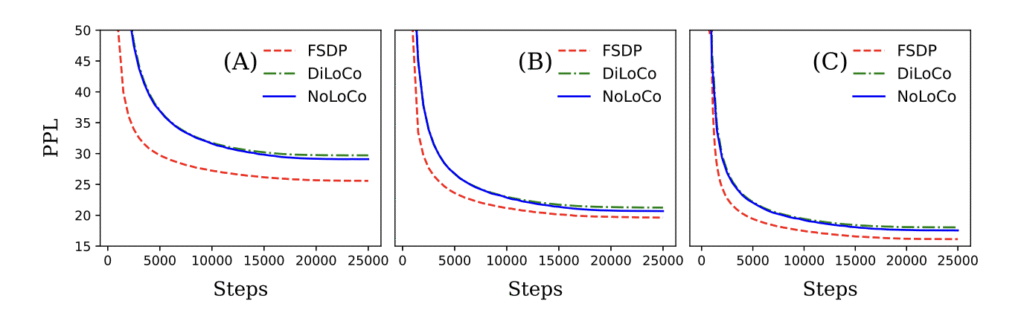
Hem teorik hem de ampirik olarak, NoLoCo’nun yakınsamayı koruyarak iletişim gereksinimlerini önemli ölçüde azalttığını gösterdik. Bu yöntemleri kullanarak, NoLoCo, milyonlarca parametreden milyarlarca parametreye kadar olan modelleri etkili bir şekilde eğitiyor. Llama tarzı modellerle, 125 milyon ile 6.8 milyar parametre arasında değişen ve 1000 kopya kullanılan deneylerimiz, NoLoCo’nun senkronizasyon adımlarının pratikte DiLoCo’dan bir order daha hızlı olduğunu ve daha hızlı yakınsadığını gösteriyor. Dahası, hem senkronizasyon stratejisi hem de değiştirilmiş optimizatör, diğer eğitim protokollerine ve model mimarilerine sorunsuz bir şekilde entegre edilebilir.
Bunun Önemi Nedir
Küresel all-reduce işleminin ortadan kaldırılması, büyük modellerin eğitilmesi için altyapı eşiğini düşürerek araştırmacıların, özel bağlantılar olmadan merkeziyetsiz donanımları daha verimli kullanmalarına olanak tanır. NoLoCo’yu, açık makine öğrenimini daha ileriye taşıyan tamamen açık bir çözüm olarak sunmaktan memnuniyet duyuyoruz.
Daha Fazla Bilgi Edin
- Makale Okuyun
- Depoyu İnceleyin — benchmark’lar, script’ler ve 100 satırlık minimal uygulama.
Tartışmaya Katılın Discord kanalımıza katılarak veya X üzerinden bizi takip ederek.