NoLoCo: Huấn luyện mô hình lớn mà không cần all-reduce

Đây là bài báo khoa học mô tả NoLoCo, một phương pháp tối ưu hóa học máy phân tán mới thay thế bước đồng bộ hóa toàn cầu bằng phương pháp gossip, cho phép huấn luyện trong các mạng lưới dị biệt với băng thông thấp.
Các phương pháp học mô hình lớn hiện đại yêu cầu trao đổi gradient thường xuyên giữa các nút, điều này đòi hỏi các kết nối tốc độ cao và độ trễ thấp. Nếu không, các nút sẽ bị “đứng yên” chờ đợi các bản cập nhật. Các phương pháp trước đây như DiLoCo làm giảm chi phí giao tiếp bằng cách giảm tần suất thực hiện all-reduce, tuy nhiên, mỗi sự kiện vẫn yêu cầu tất cả các bản sao tham gia và do đó, vẫn mang theo các hạn chế về độ trễ.
Hôm nay, chúng tôi mở rộng nghiên cứu này với NoLoCo — một phương pháp hoàn toàn loại bỏ bước đồng bộ hóa toàn cầu all-reduce. Sau một khối cập nhật cục bộ SGD ngắn, các bản sao trung bình trọng số với một bản sao ngẫu nhiên, trong khi các kích hoạt được chuyển hướng ngẫu nhiên giữa các giai đoạn của pipeline. Một bước điều chỉnh Nesterov được sử dụng để duy trì sự nhất quán của các tham số. Trong các thí nghiệm với tới 1000 GPU kết nối qua Internet, NoLoCo đạt được độ chính xác giống như phương pháp song song dữ liệu tiêu chuẩn, trong khi giảm độ trễ đồng bộ hóa khoảng 10 lần.
Những điểm nổi bật
- Không cần all-reduce
NoLoCo áp dụng phương pháp song song dữ liệu, nhưng loại bỏ đồng bộ hóa toàn cầu (all-reduce), chỉ trao đổi dữ liệu giữa các cặp nhỏ nút. - Không làm mất tốc độ hội tụ
Sự phân tán giữa các bản sao giảm nhờ việc chuyển hướng ngẫu nhiên các kích hoạt giữa các giai đoạn pipeline và bổ sung đặc biệt vào momentum Nesterov, kiểm soát sự sai lệch của trọng số. - Đồng bộ hóa nhanh hơn 10× khi quy mô lớn
Với 1000 bản sao, NoLoCo giữ nguyên độ chính xác của baseline, tăng tốc mỗi bước đồng bộ hóa so với tree all-reduce.
Cơ bản
Trong phương pháp học song song dữ liệu tiêu chuẩn, mỗi nút làm việc tính toán gradient trên mini-batch của mình và sau đó tham gia vào phép toán đồng bộ toàn cụm all-reduce, để mỗi bản sao nhận được bản cập nhật giống nhau. Giao tiếp tập thể sẽ tăng theo số lượng bản sao và bị giới hạn bởi kết nối chậm nhất. Trên các nút kết nối qua Internet, bước này chiếm ưu thế về thời gian thực thi và tiêu tốn tài nguyên tính toán. Các sơ đồ giao tiếp thấp như DiLoCo giảm tần suất thực hiện phép toán all-reduce, tuy nhiên, mỗi lần đồng bộ vẫn yêu cầu mỗi nút tham gia, dẫn đến những hạn chế về độ trễ tương tự.
NoLoCo chứng minh rằng chúng ta có thể tránh được việc đồng bộ all-reduce mà không làm giảm tốc độ hội tụ.
Cách thức hoạt động
Thay vì thực hiện phép toán all-reduce, NoLoCo chỉ đồng bộ hóa các bản sao được chọn ngẫu nhiên nhỏ (ít nhất là hai bản sao). Điều này giảm độ phức tạp thời gian đồng bộ hóa xuống khoảng ~log(N), với N là số lượng bản sao của mô hình. NoLoCo bao gồm các biện pháp bổ sung để đảm bảo rằng sự hội tụ không bị chậm lại. Lấy cảm hứng từ các phương pháp định tuyến ngẫu nhiên và động trong SWARM Parallelism và DiPaCo, NoLoCo chuyển hướng ngẫu nhiên dữ liệu huấn luyện giữa các bản sao khác nhau của các giai đoạn pipeline.
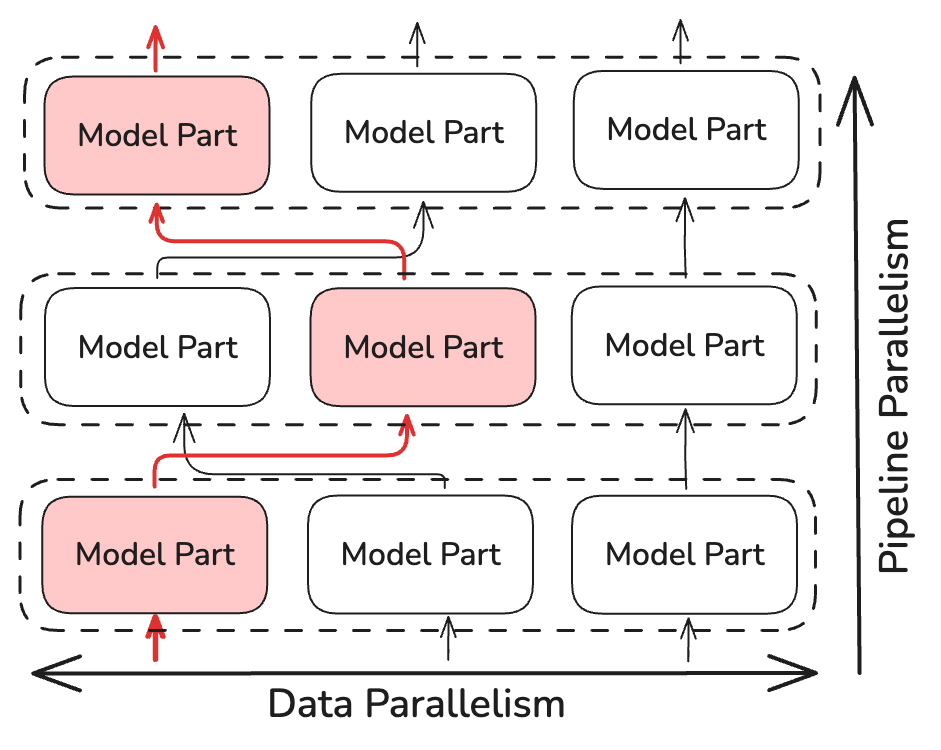
Điều này đảm bảo sự trộn lẫn đủ các gradient giữa các dữ liệu phân tán trên các bản sao song song.
NoLoCo cũng sử dụng một biến thể mới của momentum Nesterov, trong đó có một thành phần thứ ba để làm gần trọng số lại với nhau. Với thành phần bổ sung này, biểu thức đầy đủ của momentum Nesterov trở thành:
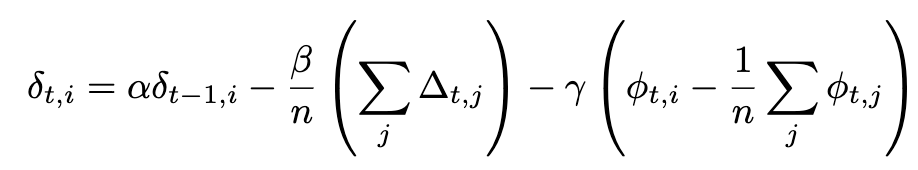
Nếu đồng bộ hóa được áp dụng cho tất cả các nút làm việc, thành phần cuối cùng biến mất, và chúng ta khôi phục lại biểu thức ban đầu của momentum Nesterov được sử dụng trong DiLoCo. Các thành phần bổ sung được minh họa trong hình dưới đây:
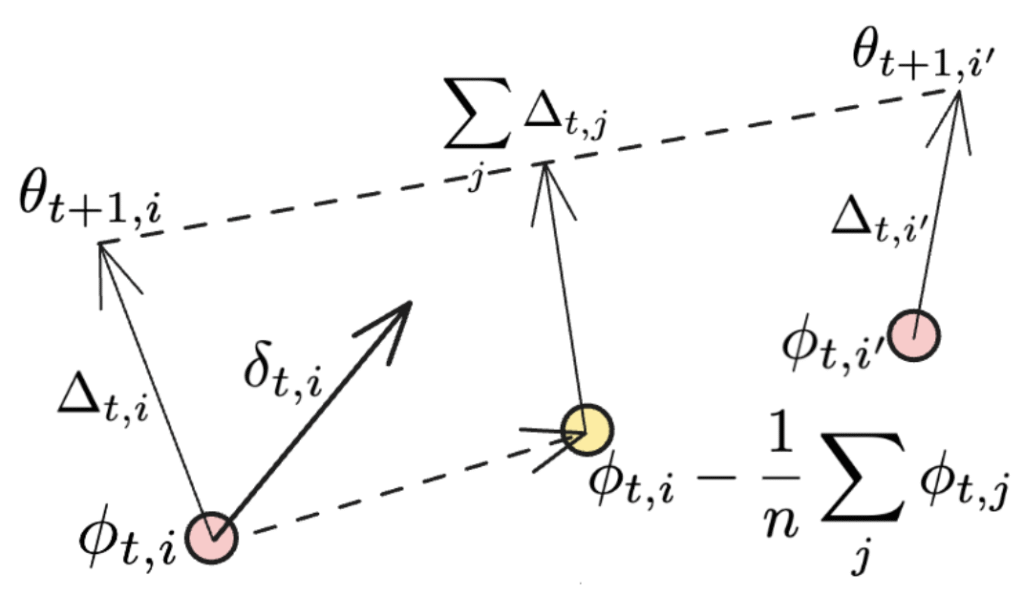
Thuật ngữ thứ hai là sự trung bình hướng, nơi mỗi công nhân riêng lẻ của NoLoCo cập nhật trọng số, trong khi thuật ngữ cuối cùng có thể được xem như một bản cập nhật khác, đưa trọng số của các công nhân khác nhau gần lại với vị trí ban đầu của chúng. Khi điều này được thực hiện trong nhiều vòng lặp, thuật ngữ thứ ba sẽ có hiệu ứng tương tự như “lăn” các mẫu trọng số trung bình của các bản sao trong quá trình huấn luyện.
Nói một cách đơn giản, NoLoCo bao gồm các bước sau:
- Giai đoạn cục bộ. Mỗi bản sao thực hiện k bước cập nhật bằng phương pháp gradient ngẫu nhiên (SGD).
- Trung bình cặp. Sau đó, nó chọn ngẫu nhiên một đối tác và trung bình trọng số, sử dụng quy tắc Nesterov, giúp kiểm soát sự lệch.
- Chuyển hướng ngẫu nhiên. Trong suốt giai đoạn cục bộ, các kích hoạt được chuyển qua các cặp đối tác ngẫu nhiên, đảm bảo sự trộn lẫn liên tục của các gradient.
Kết quả
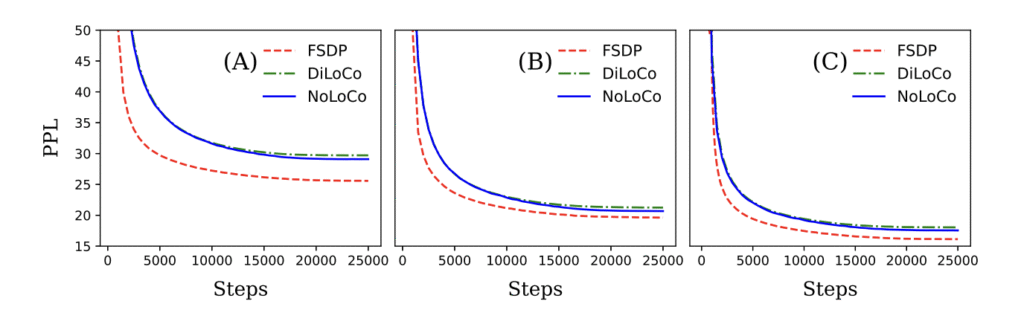
Chúng tôi đã chứng minh cả lý thuyết và thực nghiệm rằng NoLoCo giữ nguyên hội tụ, đồng thời giảm mạnh yêu cầu giao tiếp. Sử dụng các phương pháp này, NoLoCo huấn luyện hiệu quả các mô hình có từ hàng triệu đến hàng tỷ tham số. Các thí nghiệm của chúng tôi với các mô hình kiểu Llama, có số tham số từ 125 triệu đến 6,8 tỷ, sử dụng tới 1000 bản sao, cho thấy các bước đồng bộ hóa của NoLoCo nhanh hơn một đơn hàng so với DiLoCo trong thực tế, và còn hội tụ nhanh hơn. Hơn nữa, cả chiến lược đồng bộ hóa và bộ tối ưu hóa đã được chỉnh sửa có thể dễ dàng tích hợp vào các giao thức huấn luyện và kiến trúc mô hình khác.
Tại sao điều này quan trọng
Việc loại bỏ phép toán toàn cầu all-reduce giảm ngưỡng hạ tầng cho việc huấn luyện các mô hình lớn, cho phép các nhà nghiên cứu tận dụng tốt hơn các thiết bị phân tán mà không cần các kết nối chuyên biệt. Chúng tôi vui mừng giới thiệu NoLoCo như một giải pháp hoàn toàn mở để thúc đẩy giới hạn học máy mở.
Tìm hiểu thêm
- Đọc bài báo
- Khám phá kho lưu trữ – benchmark, script và triển khai tối thiểu 100 dòng.
Tham gia thảo luận trên Discord hoặc theo dõi chúng tôi trên X.