NoLoCo: обучение крупных моделей без all-reduce

Это научная статья, описывающая NoLoCo, новый метод оптимизации распределенного обучения, который заменяет этап глобальной синхронизации методом gossip, позволяя проводить обучение в гетерогенных сетях с низкой пропускной способностью.
Современные методы обучения крупных моделей требуют частого обмена градиентами между узлами, что требует высокоскоростных и низкозадержанных соединений. В противном случае узлы остаются бездействующими в ожидании обновлений. Ранее предложенные методы, такие как DiLoCo, снижают стоимость коммуникации, уменьшая частоту all-reduce, однако каждое событие всё равно включает каждую реплику и, следовательно, наследует те же ограничения по задержке.
Сегодня мы расширяем это направление исследований с помощью NoLoCo — метода, который полностью исключает глобальный шаг all-reduce. После короткого блока локальных обновлений SGD реплики усредняют веса с одной случайной репликой, в то время как активации случайным образом перенаправляются между этапами конвейера. Используется модифицированный шаг Нестерова для поддержания согласованности параметров. В экспериментах с использованием до 1000 GPU, подключённых через интернет, NoLoCo обеспечивает такую же точность на валидации, как стандартный параллелизм данных, при этом снижая задержку синхронизации примерно в 10 раз.
Основные моменты
- No all-reduce
NoLoCo применяет data-parallelism, но исключает глобальную синхронизацию all-reduce, обмениваясь данными только между маленькими парами узлов.
- No loss in convergence speed
Разброс между репликами снижается за счёт случайной маршрутизации активаций между pipeline-этапами и специального добавления в Nesterov momentum, контролирующего расхождение весов.
- 10× faster synchronisation at scale
При 1,000 реплик NoLoCo сохраняет точность baseline, ускоряя каждый шаг синхронизации по сравнению с tree all-reduce.
Основы
В стандартном обучении с параллельной обработкой данных каждый рабочий узел вычисляет градиенты на своём мини-батче, а затем участвует в общекластерной операции all-reduce, чтобы каждая реплика получила одинаковое обновление. Коллективная коммуникация масштабируется линейно с количеством реплик и ограничивается самой медленной связью. На узлах, соединённых через интернет, этот шаг доминирует по времени выполнения и тратит вычислительные ресурсы. Схемы с низким уровнем коммуникации, такие как DiLoCo, уменьшают частоту выполнения операции all-reduce, однако каждая синхронизация всё равно затрагивает каждого рабочего узла, что приводит к одинаковым ограничениям по задержке.
NoLoCo показывает, что мы можем избежать этой синхронизации all-reduce, не ухудшая сходимости.
Как это работает
Вместо выполнения операции all-reduce, NoLoCo синхронизирует только небольшие, случайно выбранные реплики (как минимум две). Это снижает сложность времени синхронизации на ~log(N), где N — количество реплик модели. NoLoCo включает дополнительные меры для обеспечения того, чтобы сходимость не замедлялась. Вдохновлённый методами динамической и случайной маршрутизации из SWARM Parallelism и DiPaCo, NoLoCo случайным образом маршрутизирует обучающие данные между различными репликами этапов конвейера.
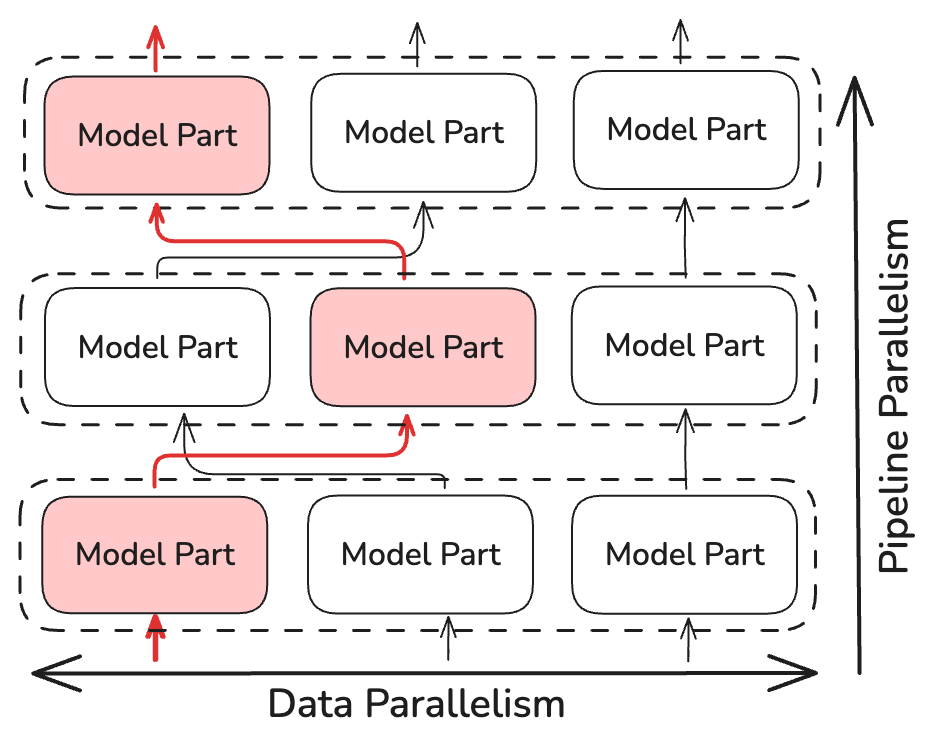
Это обеспечивает достаточное перемешивание градиентов между данными, распределёнными по параллельным экземплярам.
NoLoCo также использует новый вариант момента Нестерова, в котором добавляется третий член для приближения весов друг к другу. С учётом дополнительного члена полное выражение для момента Нестерова становится:
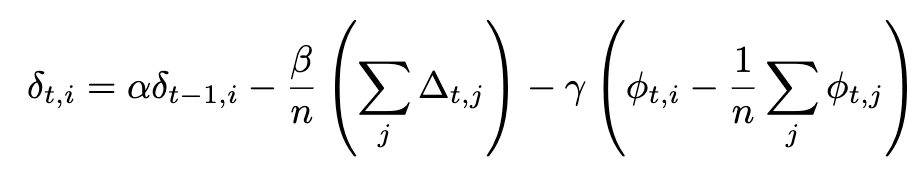
Если синхронизация применяется ко всем рабочим узлам, последний член исчезает, и мы восстанавливаем исходное выражение момента Нестерова, использованное в DiLoCo. Дополнительные члены иллюстрируются на рисунке ниже:
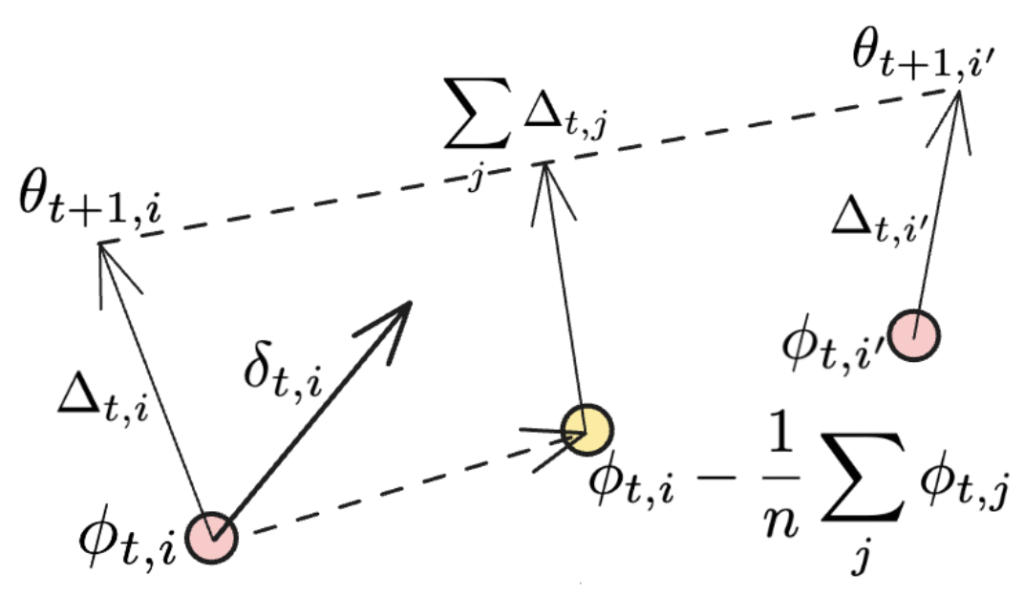
Второй термин представляет собой усреднение направления, где каждый индивидуальный работник NoLoCo обновляет веса, в то время как последний термин может быть рассмотрен как еще одно обновление, которое приближает веса различных работников к их исходной позиции. Когда это выполняется на протяжении нескольких итераций, третий термин будет иметь схожий эффект с «катанием» усредненных выборок весов реплик в процессе обучения.
Проще говоря, NoLoCo включает следующие шаги:
1. Локальная фаза. Каждая реплика выполняет k обновлений методом стохастического градиентного спуска (SGD).
2. Парное усреднение. Затем она случайным образом выбирает одного партнера и усредняет веса, используя правило Нестерова, которое ограничивает дрейф.
3. Случайная маршрутизация. В течение локальной фазы активации передаются случайным партнерским шарам, обеспечивая непрерывное смешивание градиентов.
Результаты
Мы продемонстрировали как теоретически, так и эмпирически, что NoLoCo сохраняет сходимость, существенно снижая требования к коммуникациям. Используя эти методы, NoLoCo эффективно обучает модели от миллионов до миллиардов параметров. Наши эксперименты с моделями в стиле Llama, варьирующимися от 125 миллионов до 6,8 миллиардов параметров, с использованием до 1000 реплик, показывают, что шаги синхронизации NoLoCo на порядок быстрее, чем в DiLoCo на практике, и при этом сходятся быстрее. Более того, как стратегия синхронизации, так и модифицированный оптимизатор могут быть бесшовно интегрированы в другие протоколы обучения и архитектуры моделей.
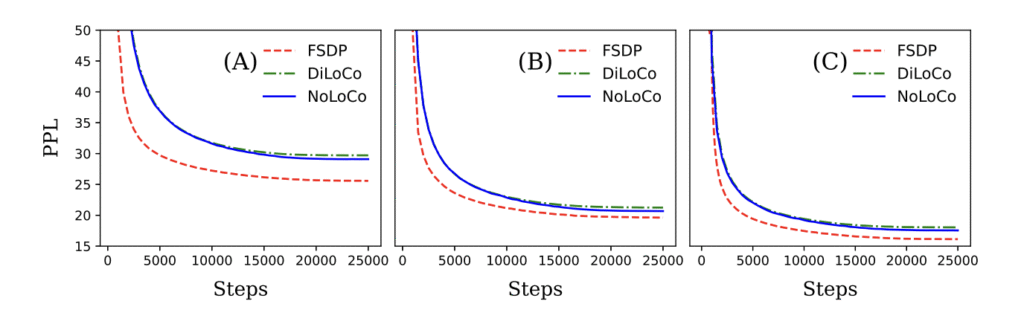
Почему это важно
Удаление глобальной операции all-reduce снижает порог инфраструктуры для обучения больших моделей, позволяя исследователям лучше использовать децентрализованное оборудование без специализированных соединений. Мы рады представить NoLoCo как полностью открытое решение для продвижения границ открытого машинного обучения.
Узнать больше
Изучить репозиторий – бенчмарки, скрипты и минимальная реализация на 100 строк.
Присоединяйтесь к обсуждению на нашем Discord или следите за нами в X.