SkipPipe:去中心化学习的高效通信方法

这篇学术论文探讨了在流水线并行训练中的高效通信。它提出了一种最优调度算法,最大化了性能和容错能力,最小化了层跳过对收敛性的影响。这将分布式训练的迭代时间减少了 55%,并确保在推理期间节点失败率高达 50% 时,模型仍能保持稳定。
最近,大型语言模型的突破得益于规模的扩展。更大的数据集和参数数量带来了更好的模型。尽管这一趋势在性能上带来了可预测的提升,但它也导致了开发成本的剧增,因为现在模型需要分布到数千个昂贵的互联节点上进行训练。
为了解决这个问题,需要新的方法来限制训练过程中的节点间通信。这为在地理分布的硬件上进行训练开辟了可能性,从而消除了当前供应链中的关键瓶颈。
大多数早期的研究集中在数据并行方法上,其中每个节点独立地训练模型的副本,并通过某些稀疏的间隔共享梯度更新。这些方法是一个很好的起点,因为它们在通信方面本身就非常高效。然而,这些方法难以扩展,因为它们要求每个节点在内存中存储整个模型,这限制了模型的大小,受到最小节点内存的制约。
介绍 SkipPipe
与纳沙泰尔大学和代尔夫特大学的研究人员一起,我们开发了 SkipPipe——一种容错的并行流水线训练方法,它动态地跳过和重新分配阶段,以优化去中心化环境中的学习。SkipPipe 展现了与传统流水线训练方法相比,减少了 55% 的训练时间,并且不影响模型的收敛性。
它还具有很高的容错性——展现出 在节点故障率高达 50% 时,推理的困惑度损失仅为 7%(即当一个模型的半数节点不可用时,我们在通过现在稀疏的模型进行推理时,仅损失 7% 的困惑度)。
与现有的数据并行训练方法不同,SkipPipe 能够训练大型模型。由于它将模型本身分布在多个节点之间,而不仅仅是分割数据集,SkipPipe 减少了每个节点的内存消耗,并消除了模型大小的限制,使得在分布式和去中心化基础设施上训练理论上无限大的模型成为可能。
它是如何工作的
SkipPipe 基于传统的流水线并行化,动态地选择每个微批次需要执行的阶段,而不是顺序地处理每个阶段。在传统的流水线中,每个微批次必须经过所有模型层,这意味着如果一个阶段延迟,所有后续阶段都必须等待。SkipPipe 允许定义跳过率(k%),从而允许在微批次中跳过某些层,如果这些层可能导致延迟。
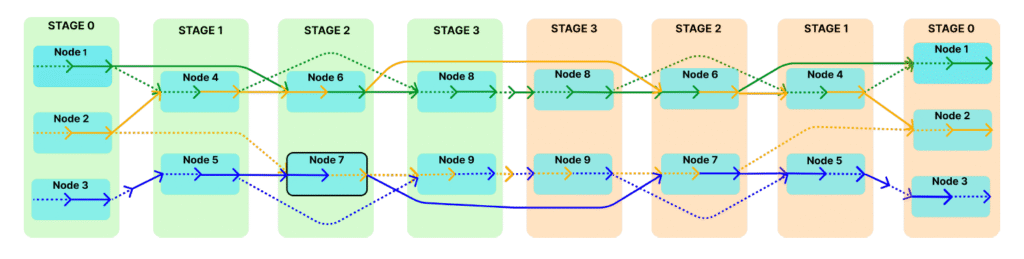
SkipPipe 使用一种新的调度算法来分析网络中可用的计算路径并选择最佳路线。这最小化了 GPU 的空闲时间,并提高了容错能力,使得系统可以绕过不工作或运行缓慢的节点。
结论
SkipPipe 为分布式(和去中心化)学习提供了一个基本的构建模块,提供了有效的通信和容错性,尤其是在现有的工作仅集中在数据并行性的情况下。通过专注于流水线并行性,我们消除了现有方法在模型大小上的限制,使得模型可以通过多个分布式节点扩展,而不仅仅是简单地复制并在并行模式下训练。
结合 协作系统 和 可信验证方法,SkipPipe 使得能够在众包计算上有效训练超大规模的前沿模型。
要了解更多,您可以阅读完整的文章 这里。
SkipPipe 完全开源,我们鼓励研究社区基于此 代码 开展自己的开发。