RL Swarm: Pekiştirmeli Öğrenme İçin Ortak Eğitim Çerçevesi

Bu, internet üzerinden işbirlikçi pekiştirmeli öğrenme gerçekleştiren eşler arası (peer-to-peer) düğümler için açık kaynaklı bir koddur (MIT Lisansı). Tüketici veya veri merkezi donanımları kullanan herkes tarafından erişilebilir.
Biz uzun zamandır inanıyoruz ki, makine öğreniminin geleceği merkeziyetsiz ve parçalanmış olacaktır. Mevcut monolitik modellerimiz, dünya çapındaki her cihazda bulunan parçalanmış parametrelerle değiştirilecektir. Araştırmamızda bu geleceğe giden farklı yolları inceledik ve yakın zamanda, pekiştirmeli öğrenmenin (RL) özellikle modellerin birbirleriyle iletişim kurarak ve birbirlerinin cevaplarını eleştirerek ortak olarak eğitildiklerinde daha etkili çalıştığını keşfettik.
Özellikle, RL ile eğitim gören modellerin, kolektif bir sürü halinde eğitildiklerinde tek başlarına eğitilmelerine kıyasla daha hızlı öğrendiklerini tespit ettik. Mekanizmanın detaylarını buradan okuyabilir veya teknolojiyi canlı gösterimde görmek için buraya katılabilirsiniz.
Nasıl Çalışır
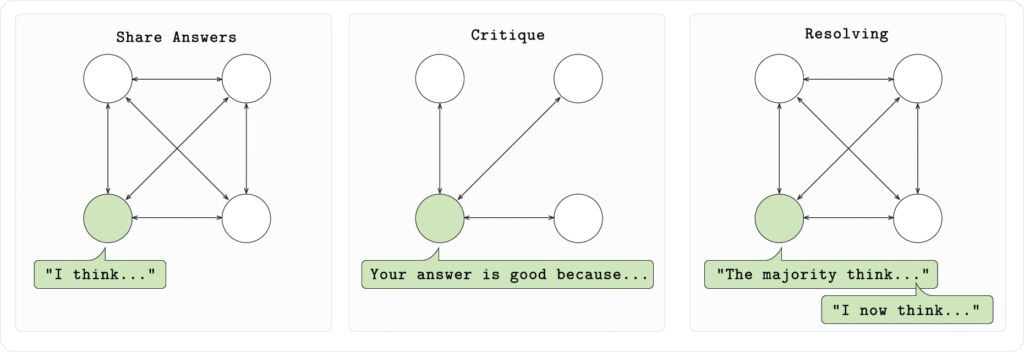
Kurulumumuzda, her bir düğüm Qwen 2.5 1.5B modelini çalıştırır ve matematiksel problemleri (GSM8K) üç aşamada çözer:
- Aşama 1 (Cevap):
Her model, belirtilen formatta kendi akıl yürütmesini ve cevabını çıkararak problemi bağımsız olarak çözer. - Aşama 2 (Eleştiri):
Her model, diğer modellerin sunduğu cevapları değerlendirir ve geri bildirimde bulunur. - Aşama 3 (Çözüm):
Her model, her bir soru için en iyi cevabı oylayarak, nihai revize edilmiş cevabı sağlar.
Deneylerimizde, bu sistemin öğrenmeyi hızlandırdığını, modellerin daha az eğitim adımıyla daha doğru cevaplar verdiğini keşfettik.

Yukarıdaki grafikler, sürüdeki bir düğümün Tensorboard sonuçlarını göstermektedir. Her grafikte, çok aşamalı oyunun turları arasındaki “sıfırlamaların” bir sonucu olarak döngüsel bir davranış gözlemlenir. Tüm grafiklerde x-ekseni, sürüye katılma üzerinden geçen süreyi temsil eder. Soldan sağa doğru y-eksenleri için şunları görürüz:
i) “Fikir birliği doğruluk ödülü”: Bu sürü katılımcısının en iyi yanıt için seçimlerini doğru şekilde biçimlendirdiği ve seçilen yanıtın matematiksel olarak doğru olduğu durumları ölçer;
ii) Toplam ödül: Çeşitli kural tabanlı ödüllerin ağırlıklı toplamıdır (yanıtların biçimlendirmesinin ve matematiksel/mantıksal doğruluğunun kontrol edilmesi gibi);
iii) Eğitim kaybı: Ödül maksimizasyonu için geri besleme sinyalini yakalar ve “temel” Büyük Dil Modeli’ni (LLM) güncellemek için yayılır;
iv) Modelin yanıt tamamlama uzunluğu: Çıktı yanıtındaki token sayısını yakalar (bu, modellerin akranları tarafından eleştirildiğinde daha öz ve kısa yanıt vermeyi öğrendiğini gösterir).
Topluluğa Katılım
Bu sistemi tanıtmak ve deneyleri ölçeklendirmek için, herkesin katılabileceği canlı bir gösterim yayınlıyoruz. Bu, internet üzerinden RL eğitim toplulukları oluşturmak için tamamen açık bir sistemdir.
Swarm-node başlatarak, yeni bir swarm kümesi oluşturabilir veya zaten var olan bir düğüme onun genel adresini kullanarak bağlanabilirsiniz. Her bir küme, modeli kolektif olarak geliştirmek için Hivemind tabanlı bir dedikodu sistemi kullanarak pekiştirmeli öğrenmeyi (RL) uygulamaktadır.
Entegre istemciyi başlatmak, kümeye bağlanmanıza, mesajlar almanıza ve modelinizi kolektifin bir parçası olarak yerel olarak eğitmenize olanak tanır. Gelecekte swarm sistemi için daha fazla deney başlatacağız ve topluluğun geniş katılımını memnuniyetle karşılıyoruz.
***
RL Swarm, makine öğreniminin geleceğine bir bakış açısı sunmaktadır. Katılımcılar arasında kolektif zekanın, sınırlı kapalı laboratuvarlar yerine kullanıldığı bir ortak RL çerçevesi sağlar. Ölçekleme, her cihazı dünyada birbirine bağlayan açık bir hesaplama ağı gerektirecektir. Detaylar — yakında.