CheckFree: 无检查点的故障恢复训练

这篇学术论文介绍了一种名为CheckFree的创新性方法,用于分布式训练中的故障恢复。该方法无需检查点或冗余计算,可在频繁发生故障的环境中实现高效训练。
主要要点
- 与传统检查点相比提高了最多 1.6 倍的速度:CheckFree 和 CheckFree+ 在训练阶段频繁发生故障时,与传统检查点相比,可以提高训练时间的速度,最多可达到 1.6 倍。
- 无需检查点的新恢复方法:CheckFree 使用相邻阶段的权重来近似丢失的阶段权重。
背景
在先进的恢复策略中,模型权重会定期检查点化(周期性存储)到无故障的集中式存储中。这种做法成本极高,例如在高速网络连接条件下(假设超过500 Mb/s),保存LLaMa 70B模型的一个检查点就需要超过20分钟。当发生故障时,模型会完全回滚到上一个检查点,从而导致可能数小时的训练成果丢失。Bamboo提出了一种替代检查点的冗余计算方法——将阶段权重存储在前一阶段,并在副本上冗余执行每个微批量的前向传播。这样当发生单一故障时,训练可以立即恢复。然而,这种方法对大型模型效果有限,因为每个节点需要双倍内存来存储冗余层。CheckFree和CheckFree+为大规模地理分布式训练提供了可行替代方案,因为它们不需要额外的计算或通信开销。
原理
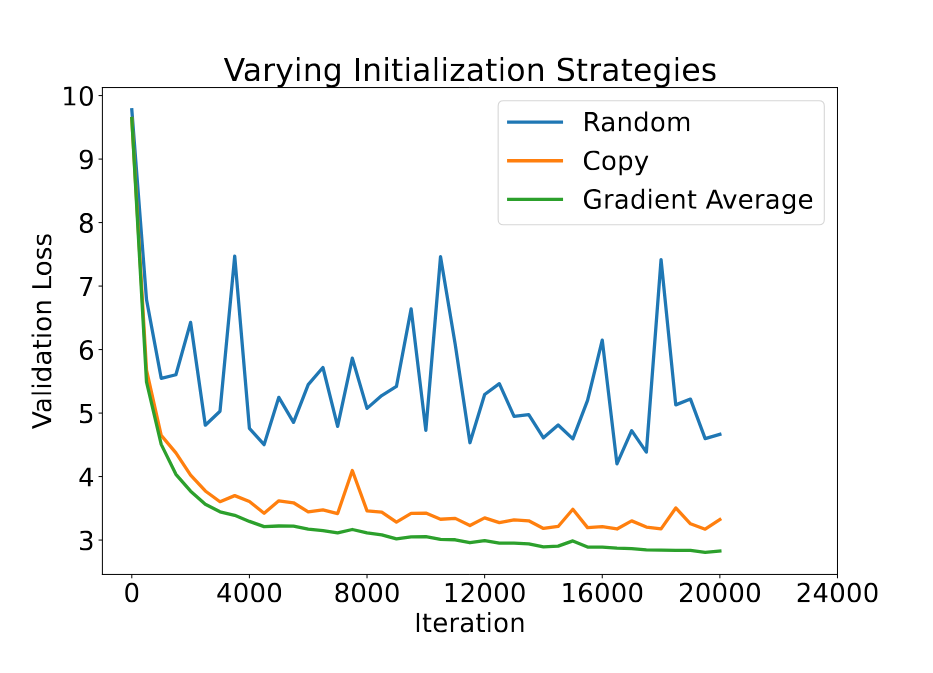
当发生故障时,丢失的阶段通过加权平均其相邻的两个阶段来恢复。这利用了 LLM 层的自然冗余,正如之前的研究所示,删除几个层并不会对模型的性能产生显著影响。我们通过实验证明,平均法显著优于通常在层堆叠研究中使用的简单复制方法。
一种简单的平均方法是均匀地平均两个阶段。然而,这种平均方法没有区分阶段的重要性和收敛性,从而导致模型整体收敛速度较慢。因此,CheckFree 使用了该阶段的最后梯度范数权重。从概念上讲,这为尚未收敛的阶段赋予了更大的权重,部分将它们的功能转移到新的阶段。为了让新初始化的阶段“赶上进度”,CheckFree 在恢复后稍微增加了几个训练步长的学习率。
然而,这种策略无法恢复第一个和最后一个阶段的权重,因为没有相邻的阶段可以用于平均。为此,我们提出了 CheckFree+。它通过异步执行来恢复这些极端阶段:每两个小批量就交换前两个和最后两个阶段的顺序,允许中间层学习其邻居的行为,类似于冗余计算,但无需额外的内存或计算开销。在发生故障时,可以复制“冗余”阶段以替代丢失的阶段。
结果
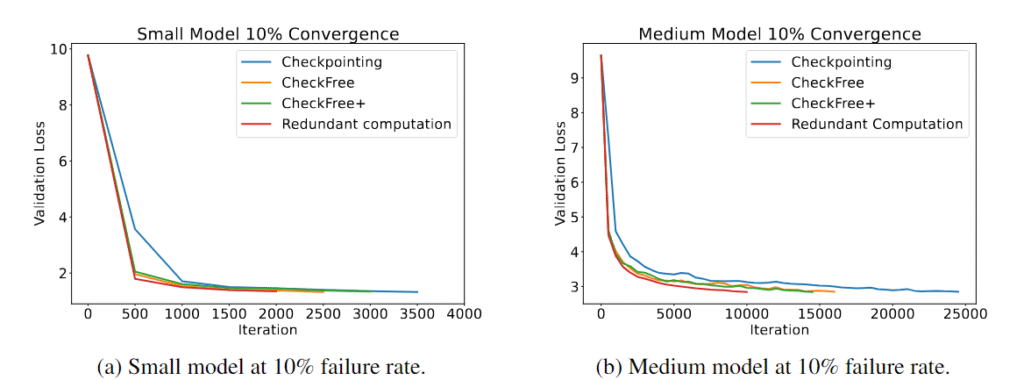
我们广泛评估了 CheckFree 和 CheckFree+,故障率从每小时 5% 到 16% 不等,与传统的检查点和冗余计算方法进行了比较。我们观察到,在不同的模型大小下,CheckFree 和 CheckFree+ 能够比现有方法更快地在实际训练时间上收敛。然而,我们的方法相较于没有故障的基准线(相当于冗余计算的收敛)在迭代收敛性上有所下降。但由于其轻量级的恢复过程,CheckFree 和 CheckFree+ 可以提供更高的吞吐量,这使得它们非常适合大规模的地理分布式训练大规模语言模型。
为什么这很重要
在去中心化训练中,节点可以随时加入或退出网络,这可能导致整个阶段的故障。即使在分布式训练中,如果相应的节点在同一区域计划,也可能丢失整个阶段。检查点可能因频繁重启而带来大量开销,而冗余计算对于大型模型来说可能因为内存线性增长而变得不可行。CheckFree 提供了一种高效的方式,在不需要额外计算或通信的情况下恢复 LLM 的训练。